Я
ЯндексНе указана
ML-разработчик в Вертикали
Удалённо
Python · SQL · CatBoost · PyTorch · Hugging Face · FastAPI · Docker · Airflow · MLOps · NLP · Time Series
+11 навыковml разработчик - готовый пример резюме для профессии и руководство по составлению с советами бесплатно.
Резюме ML-разработчика — это не просто список технологий и мест работы. Это технический продукт, который должен пройти два критических фильтра: автоматическую систему отбора (ATS) и 30-секундный просмотр техлида. По статистике HeadHunter, на одну вакансию ML Engineer приходится 87 откликов, и только 5-7 из них получают приглашение на интервью.
В этом руководстве вы получите пошаговую инструкцию по созданию резюме, которое выделит вас среди конкурентов. Мы разберем каждый раздел с примерами для разных уровней специалистов — от Junior до Lead. Вы узнаете, как превратить технические задачи в измеримые бизнес-результаты, какие метрики убеждают работодателей и как адаптировать документ под специфику вакансии.
Материал основан на анализе 200+ успешных резюме ML-инженеров и интервью с техническими рекрутерами крупных IT-компаний.
Профессия ML Engineer находится на стыке разработки, исследований и бизнеса. Это создает уникальные требования к резюме:
ATS-системы с техническим уклоном. Рекрутеры настраивают автоматический отбор по ключевым словам: названиям фреймворков (PyTorch, TensorFlow), методам (Computer Vision, NLP), инструментам деплоя (Kubernetes, MLflow). Если ваше резюме не содержит релевантных терминов из описания вакансии, оно может не дойти до живого человека.
30 секунд на первое впечатление. Техлид или старший разработчик сканирует резюме в поисках сигналов: какие модели вы строили, на каких данных, какой получили результат. Абстрактные формулировки вроде "занимался Machine Learning" отсеиваются моментально.
Баланс между наукой и практикой. Работодатели ищут людей, которые не только знают теорию нейросетей, но и умеют довести модель до production. Важно показать полный цикл: от исследования и экспериментов до деплоя и мониторинга в бою.
Актуальность стека. Технологии в ML меняются быстро. В 2026 году работодатели обращают внимание на опыт работы с большими языковыми моделями (LLM), vector databases, MLOps-инструментами. Устаревшие технологии без контекста могут сыграть против вас.
Совет эксперта: Создайте базовую версию резюме со всеми проектами и навыками, а затем адаптируйте её под каждую вакансию, выдвигая на первый план релевантный опыт. Это увеличивает шанс прохождения ATS на 60-70%.
Первый экран резюме должен мгновенно ответить на вопрос: кто вы и как с вами связаться. Неправильное позиционирование в заголовке может стоить вам просмотра.
Ваша должность в заголовке — это ключевой якорь для поиска. Используйте формулировки, по которым рекрутеры ищут кандидатов:
Удачные варианты:
Неудачные варианты:
Если вы специализируетесь в конкретной области, отразите это в заголовке: "Computer Vision Engineer" или "NLP Engineer" работают лучше, чем общее "ML Developer", при поиске на узкопрофильную вакансию.
Иван Петров
Machine Learning Engineer
Email: ivan.petrov@email.com
Telegram: @ivan_petrov
GitHub: github.com/ivanpetrov
LinkedIn: linkedin.com/in/ivanpetrov
Город: Москва (возможен релокейт / рассматриваю удаленку)
Что обязательно указать:
Что не указывать:
Совет эксперта: Если вы открыты к релокации или удаленной работе, укажите это явно в контактах. Это расширит круг подходящих вакансий и сэкономит время рекрутерам.
Блок "О себе" (Summary) — это ваша профессиональная самопрезентация в 3-4 предложениях. Задача: за 10 секунд дать рекрутеру понимание вашего уровня, специализации и ключевой ценности.
Формула эффективного Summary:
[Должность] с [X лет] опытом в [специализация] | [Ключевая экспертиза] | [Главное достижение с метрикой] | [Что ищете сейчас]
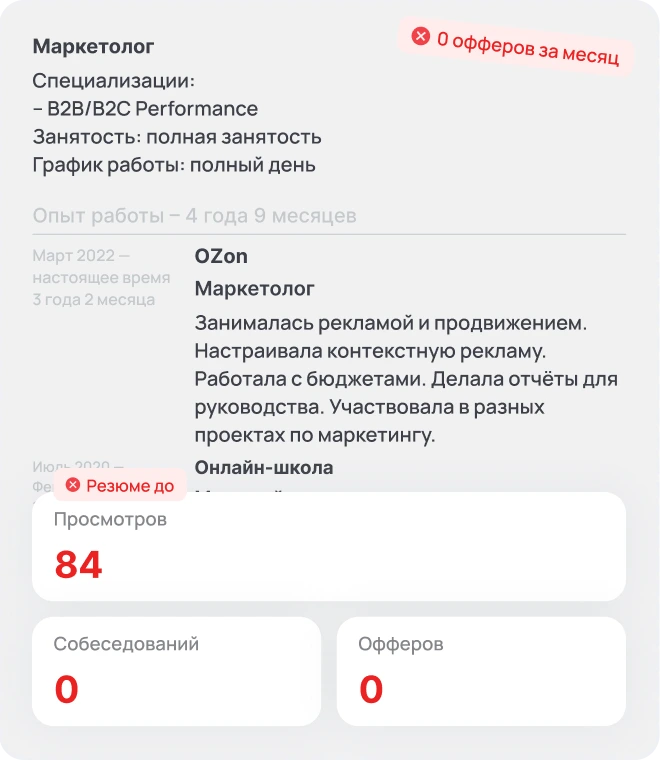
Сравните, как ИИ-резюмейкер Quick Offer превращает резюме с hh.ru в профессиональное

Junior ML Engineer (0-1.5 года опыта):
Junior ML Engineer с опытом разработки моделей Computer Vision и NLP в учебных и pet-проектах.
Владею Python, TensorFlow, PyTorch, scikit-learn. Реализовал 5 проектов на GitHub (общее количество
stars — 230+), включая систему распознавания объектов на YOLOv8 с accuracy 89% на открытом датасете.
Прошел специализацию Deep Learning от Andrew Ng и участвовал в 3 соревнованиях Kaggle (лучший
результат — топ 15%). Ищу позицию Junior ML Engineer для применения знаний в коммерческих проектах
и роста под руководством опытной команды.
Что работает:
Middle ML Engineer (1.5-4 года опыта):
ML Engineer с 3 годами опыта разработки и внедрения моделей в production для e-commerce и fintech.
Специализируюсь на рекомендательных системах и NLP. Разработал систему персонализированных
рекомендаций, которая увеличила конверсию на 28% и принесла дополнительные 15 млн руб. выручки
за квартал. Опыт работы с полным ML-пайплайном: от EDA и feature engineering до деплоя на
Kubernetes и A/B тестирования. Стек: Python, PyTorch, FastAPI, Docker, Airflow. Ищу возможности
для работы над сложными ML-задачами с влиянием на ключевые продуктовые метрики.
Что работает:
Senior / Lead ML Engineer (4+ года опыта):
Senior ML Engineer с 6 годами опыта проектирования ML-систем для продуктов с аудиторией 5+ млн
пользователей. Специализация: Computer Vision, MLOps, архитектура ML-платформ. Руководил командой
из 4 ML-инженеров при создании платформы автоматического контроля качества на производстве,
сократившей брак на 34% и сэкономившей компании $1.2 млн в год. Спроектировал MLOps-инфраструктуру
на базе Kubernetes, Kubeflow и MLflow, ускорившую деплой моделей с 2 недель до 1 дня. Эксперт в
PyTorch, TensorFlow, AWS SageMaker. Ищу роль Lead ML Engineer для создания ML-продуктов с нуля
и развития инженерной культуры в команде.
Что работает:
Совет эксперта: Не пишите абстрактное "ответственный, целеустремленный, быстро обучаюсь". Каждое утверждение подкрепляйте фактом: вместо "быстро обучаюсь" — "за 2 месяца освоил PyTorch и мигрировал 5 моделей с TensorFlow, сократив inference time на 35%".
Раздел навыков — это ключевая точка для прохождения ATS и быстрой оценки вашей экспертизы техлидом. Хаотичный список из 40 технологий вредит: рекрутер не понимает, что вы знаете действительно хорошо.
Разделите технологии на 4-5 логических категорий. Внутри каждой перечисляйте от самых сильных к менее освоенным.
Пример структуры для Middle ML Engineer:
ТЕХНИЧЕСКИЕ НАВЫКИ
Языки программирования:
Python (продвинутый), SQL (средний), C++ (базовый)
ML/DL фреймворки и библиотеки:
PyTorch, TensorFlow, scikit-learn, XGBoost, LightGBM, Hugging Face Transformers, ONNX
Инструменты разработки и версионирования:
Git, Docker, Jupyter, VS Code, DVC (Data Version Control)
MLOps и деплой:
Kubernetes, FastAPI, MLflow, Airflow, CI/CD (GitHub Actions), Prometheus, Grafana
Облачные платформы:
AWS (SageMaker, EC2, S3, Lambda), Google Cloud Platform (Vertex AI, BigQuery)
Области специализации:
Computer Vision (объектная детекция, сегментация), NLP (text classification, named entity recognition),
рекомендательные системы
Что работает в этой структуре:
Работодатели обращают внимание на технологии, которые решают современные задачи:
Обязательный минимум:
Дополнительные преимущества:
Устаревшие технологии без контекста:
Если вы указываете Theano, Caffe или другие фреймворки, которые уже не поддерживаются активно, добавьте контекст: "опыт миграции моделей с Caffe на PyTorch". Просто перечисление старых технологий создает впечатление, что вы не следите за индустрией.
Избегайте:
Совет эксперта: Адаптируйте порядок технологий под вакансию. Если в описании на первом месте PyTorch и NLP, поставьте эти навыки в начало своих категорий. ATS-системы учитывают не только наличие, но и приоритет ключевых слов.
Это самый важный раздел резюме. Здесь вы доказываете свою ценность через конкретные результаты. Задача — превратить технические задачи в понятные бизнесу достижения.
Для каждого места работы используйте единую структуру:
Название должности
Компания, город — Период работы (мм.гггг — мм.гггг)
[Краткое описание компании и вашей роли в 1 предложении]
Ключевые проекты и достижения:
- [Проект 1 с метриками]
- [Проект 2 с метриками]
- [Проект 3 с метриками]
Технологии: [Стек, который использовали на этой позиции]
Каждое достижение описывайте по формуле: Действие + Контекст + Результат
Действие: Глагол в прошедшем времени (разработал, оптимизировал, внедрил)
Контекст: Какую задачу решали, какими методами, в каких условиях
Результат: Измеримое улучшение бизнес или технической метрики
Было (плохо):
- Работал с данными и строил модели машинного обучения
- Участвовал в проектах по Computer Vision
- Писал код на Python
Стало (хорошо):
Junior ML Engineer
Стартап EdTech, Москва — 06.2023 — настоящее время
Разработка ML-компонентов для образовательной платформы с 15 тыс. пользователей.
- Разработал модель классификации сложности учебных текстов на основе BERT (ruBERT),
достигнув F1-score 0.84 на тестовой выборке из 5 тыс. текстов, что позволило
автоматизировать процесс подбора материалов и сократить время методистов на 12 часов в неделю
- Реализовал baseline решение для задачи распознавания рукописных формул с использованием
CNN + LSTM архитектуры, получив accuracy 78% на датасете из 10 тыс. изображений
- Создал автоматизированный pipeline для обработки и аугментации изображений с помощью Albumentations,
что увеличило размер обучающей выборки в 4 раза и улучшило качество моделей на 6%
- Настроил систему версионирования данных и экспериментов с использованием DVC и MLflow,
что ускорило итерации команды и обеспечило воспроизводимость результатов
Технологии: Python, PyTorch, Transformers, scikit-learn, Docker, DVC, MLflow, PostgreSQL
Почему это работает:
Было (плохо):
- Разрабатывал рекомендательные системы
- Улучшал качество моделей
- Деплоил модели в production
Стало (хорошо):
ML Engineer
E-commerce компания (fashion), Санкт-Петербург — 03.2021 — 05.2024
Разработка и внедрение ML-систем для интернет-магазина с оборотом 500 млн руб./год
и аудиторией 200 тыс. активных пользователей в месяц.
- Спроектировал и внедрил гибридную рекомендательную систему (collaborative filtering +
content-based на BERT embeddings), которая увеличила CTR с 2.1% до 3.4% (+62%) и подняла
средний чек на 18%, принеся дополнительные 3.2 млн руб. выручки в месяц
- Оптимизировал пайплайн обучения моделей ранжирования: распараллелил feature engineering
с Apache Spark, внедрил online learning для быстрого обновления, сократив время
переобучения с 6 часов до 45 минут и повысив актуальность рекомендаций
- Построил MLOps-инфраструктуру для автоматического деплоя моделей: настроил CI/CD pipeline
с автоматическим тестированием (unit, integration, A/B tests), деплой на Kubernetes
с canary release, мониторинг метрик в Grafana, что сократило time-to-production с 2 недель до 3 дней
- Провел серию экспериментов по оптимизации моделей NLP для категоризации товаров:
тестировал FastText, BERT, DeBERTa, применил knowledge distillation для уменьшения
размера модели в 4 раза при падении accuracy всего на 2%, что позволило запустить
модель на CPU и снизить инфраструктурные расходы на $800/месяц
- Внедрил систему мониторинга качества моделей в production с автоматическими алертами
при data drift и performance degradation, что позволило выявлять проблемы на 3-5 дней
раньше их влияния на бизнес-метрики
Технологии: Python, PyTorch, TensorFlow, Transformers, XGBoost, FastAPI, Docker, Kubernetes,
Apache Spark, Airflow, MLflow, Prometheus, Grafana, PostgreSQL, Redis, AWS (S3, EC2, SageMaker)
Почему это работает:
Было (плохо):
- Руководил ML-командой
- Разрабатывал стратегию применения ML в компании
- Работал над сложными проектами
Стало (хорошо):
Lead ML Engineer
Fintech компания (кредитование), Москва — 06.2020 — 02.2025
Руководство ML-направлением в компании с портфелем 1.2 млрд руб. Управление командой
из 5 ML-инженеров и 2 дата-инженеров.
- Спроектировал и запустил ML-платформу для скоринга заемщиков с нуля: разработал архитектуру
системы на AWS (SageMaker, Lambda, Step Functions), внедрил ансамбль из 7 моделей
(gradient boosting + нейросети для обработки документов), что позволило обрабатывать
15 тыс. заявок в день с latency < 3 секунд и снизить долю дефолтов на 23% (экономия $2.1 млн/год)
- Руководил проектом по внедрению Computer Vision для автоматической верификации документов:
координировал работу команды, выбрал архитектуру (Faster R-CNN для детекции + Tesseract OCR),
организовал разметку 50 тыс. документов, достигли accuracy распознавания 94.5%,
автоматизировали 78% проверок и сократили время обработки заявки с 15 минут до 2 минут
- Построил инфраструктуру для continuous training и мониторинга моделей: спроектировал
архитектуру feature store на Feast, настроил автоматическое переобучение при детекции drift,
внедрил shadow mode testing для безопасного раската новых версий, что позволило поддерживать
актуальность моделей без участия инженеров и увеличило скорость итераций команды в 3 раза
- Разработал technical roadmap развития ML в компании на 2 года: провел аудит существующих
решений, приоритизировал 12 инициатив по критерию бизнес-импакт/сложность, защитил
бюджет $400k, что обеспечило рост выручки от ML-продуктов на 35% год к году
- Выстроил процессы разработки ML-моделей: внедрил code review, unit/integration тесты
для ML-кода, стандарты документации экспериментов, процессы A/B тестирования,
что снизило количество инцидентов в production на 67% и повысило скорость онбординга
новых членов команды с 2 месяцев до 3 недель
- Нанял и развил команду ML-инженеров: провел 40+ интервью, нанял 4 специалистов,
разработал план развития для каждого, 2 инженера выросли с Middle до Senior за 1.5 года
Технологии: Python, PyTorch, TensorFlow, XGBoost, LightGBM, FastAPI, Docker, Kubernetes,
AWS (SageMaker, Lambda, Step Functions, S3), Feast, Airflow, MLflow, Terraform, PostgreSQL, ClickHouse
Почему это работает:
| Категория | Глаголы |
|---|---|
| Разработка | Разработал, Спроектировал, Реализовал, Создал, Построил |
| Улучшение | Оптимизировал, Улучшил, Повысил, Ускорил, Масштабировал |
| Внедрение | Внедрил, Запустил, Развернул, Интегрировал, Мигрировал |
| Исследование | Исследовал, Экспериментировал, Протестировал, Валидировал, Сравнил |
| Автоматизация | Автоматизировал, Настроил, Стандартизировал, Упростил |
| Лидерство | Руководил, Координировал, Организовал, Обучил, Менторил |
Подбираем лучшие вакансии и откликаемся за вас. До 100 автооткликов в день.

Технические метрики качества:
Производительность:
Бизнес-метрики:
Процессные метрики:
Совет эксперта: Всегда указывайте "было → стало" для метрик. Вместо "достиг accuracy 92%" пишите "повысил accuracy с 85% до 92%". Это показывает ваш вклад, а не стартовое состояние проекта.
Если у вас мало или нет коммерческого опыта, раздел с проектами становится критически важным. Это ваш способ доказать навыки на практике.
GitHub репозитории:
Создайте 3-5 качественных проектов, которые демонстрируют разные навыки:
1. Классический ML проект (например, предсказание оттока клиентов):
- Полный цикл: EDA, feature engineering, сравнение моделей, кросс-валидация
- Чистый код с комментариями
- Jupyter notebook с визуализациями
- README с описанием задачи, данных, результатов
2. Deep Learning проект (например, классификация изображений или NLP-задача):
- Использование современных архитектур (ResNet, BERT)
- Transfer learning с дообучением
- Анализ ошибок модели
- Сохраненная обученная модель
3. End-to-end проект с деплоем:
- Модель, обернутая в API (FastAPI, Flask)
- Dockerfile для контейнеризации
- Опционально: развернуто на Heroku/AWS/GCP с демо-интерфейсом
Kaggle competitions:
Участие в соревнованиях показывает умение работать с реальными данными:
Онлайн-курсы и сертификаты:
Для Junior это важный сигнал структурного обучения:
ПРОЕКТЫ И ПОРТФОЛИО
GitHub: github.com/username (5 репозиториев ML-проектов, 240+ stars)
Система рекомендаций фильмов на основе collaborative filtering
github.com/username/movie-recommender
- Разработал рекомендательную систему на датасете MovieLens (25 млн оценок)
- Реализовал и сравнил 4 подхода: ALS, SVD, нейросетевой collaborative filtering, гибридную модель
- Лучший результат: RMSE 0.82, что на 15% лучше baseline
- Создал REST API на FastAPI и веб-интерфейс для демонстрации
Стек: Python, PyTorch, Surprise, FastAPI, Docker
Классификация новостей по тематикам с использованием BERT
github.com/username/news-classifier
- Собрал и разметил датасет из 15 тыс. новостных статей на русском языке (8 категорий)
- Дообучил ruBERT для задачи классификации, достигнув F1-score 0.91
- Применил knowledge distillation для сжатия модели в 3 раза с падением качества только на 2%
- Провел анализ ошибок и визуализацию эмбеддингов с t-SNE
Стек: Python, Transformers, PyTorch, scikit-learn, Weights & Biases
Kaggle: kaggle.com/username
- Titanic: топ 7% (accuracy 0.81)
- House Prices: топ 12% (RMSE 0.117)
- NLP with Disaster Tweets: топ 18% (F1 0.84)
Что делает портфолио сильным:
Совет эксперта: Один очень качественный проект с чистым кодом, подробной документацией и развернутым API стоит больше, чем пять небрежных jupyter notebooks. Работодатели смотрят на качество исполнения, не на количество.
AI создаст 3 письма под ваше резюме и подберёт лучшее под каждую вакансию.

ОБРАЗОВАНИЕ
Московский государственный университет
Магистратура, Прикладная математика и информатика — 2020-2022
Диплом: "Применение ансамблевых методов для предсказания временных рядов"
Санкт-Петербургский политехнический университет
Бакалавриат, Программная инженерия — 2016-2020
Средний балл: 4.8/5.0
Правила:
Топ сертификатов для ML-инженера:
СЕРТИФИКАЦИИ И КУРСЫ
- Deep Learning Specialization, Coursera (Andrew Ng) — 2023
- Machine Learning Engineering for Production (MLOps), Coursera — 2024
- TensorFlow Developer Certificate — 2023
- AWS Certified Machine Learning – Specialty — 2024
- Fast.ai: Practical Deep Learning for Coders — 2022
Что ценится:
Что не стоит указывать:
Проблема: Указано 40 технологий, но непонятно, что вы с ними реально делали.
Плохо:
Навыки: Python, TensorFlow, PyTorch, scikit-learn, Keras, XGBoost, LightGBM, CatBoost,
ONNX, NumPy, Pandas, Matplotlib, Seaborn, OpenCV, PIL, NLTK, spaCy, Gensim, Transformers,
Datasets, Tokenizers...
Хорошо:
Разбить на категории и подтвердить применение в описании опыта:
ML/DL фреймворки: PyTorch (основной, 3+ года), TensorFlow (2 года), scikit-learn
В опыте работы:
- Разработал 5 production-моделей на PyTorch для задач Computer Vision
- Мигрировал legacy модели с TensorFlow 1.x на TensorFlow 2.x
Проблема: Перечисление того, что входило в должностные обязанности, без измеримых результатов.
Плохо:
- Разрабатывал модели машинного обучения
- Занимался предобработкой данных
- Участвовал в деплое моделей
- Работал в команде над проектами
Хорошо:
- Разработал модель предсказания оттока клиентов на градиентном бустинге,
достигнув AUC-ROC 0.89, что позволило удержать 340 клиентов и сохранить
$180k MRR за квартал
Проблема: Одно и то же резюме отправляется на вакансии Computer Vision Engineer и NLP Engineer.
Решение:
Проблема: Резюме читается как научная статья, полная технических терминов, но без связи с бизнесом.
Плохо:
- Применил архитектуру U-Net с ResNet50 энкодером для задачи сегментации,
достигнув IoU 0.87 на валидационной выборке
Хорошо:
- Внедрил модель автоматической сегментации дефектов на производственной линии
(U-Net + ResNet50, IoU 0.87), что позволило выявлять 94% брака автоматически
и сократить затраты на контроль качества на $15k/месяц
Проблема: Junior-специалисты перегружают резюме курсовыми работами, дипломом, теоретическими знаниями.
Плохо:
ОБРАЗОВАНИЕ
Диплом: "Исследование эффективности различных архитектур сверточных
нейронных сетей для задачи классификации изображений"
Научный руководитель: проф. Иванов И.И.
Оценка: отлично
Курсовые работы:
- "Анализ методов оптимизации нейронных сетей"
- "Сравнительный анализ алгоритмов кластеризации"
Хорошо:
ОБРАЗОВАНИЕ
МГУ, Магистр, Прикладная математика — 2022-2024
Диплом: разработал систему рекомендаций на основе графовых нейросетей
(код на GitHub)
Работодателю важнее увидеть практические проекты, чем академические регалии.
Шаг 1: Анализ описания вакансии
Выпишите из описания:
Шаг 2: Выделение релевантного опыта
Переставьте местами проекты так, чтобы первым шел наиболее релевантный.
Пример:
Вакансия: Computer Vision Engineer для autonomous driving
Ваше резюме:
Шаг 3: Адаптация ключевых слов
Если в вакансии используются термины "object detection", "semantic segmentation", "3D point clouds", убедитесь, что эти же термины присутствуют в вашем резюме.
Шаг 4: Корректировка Summary
Перепишите раздел "О себе" с акцентом на специфику вакансии:
Для вакансии Computer Vision в медтехе:
ML Engineer с 3 годами опыта разработки Computer Vision решений для анализа медицинских изображений.
Специализируюсь на задачах сегментации и детекции патологий на рентгеновских снимках и МРТ.
Разработал модель детекции пневмонии с sensitivity 94%, внедренную в 2 клиниках...
Совет эксперта: Создайте файл с несколькими версиями резюме: "CV_ComputerVision.pdf", "CV_NLP.pdf", "CV_MLOps.pdf". Это сэкономит время при отклике на вакансии разного профиля.
Перед отправкой резюме пройдитесь по этому списку:
Общая структура:
Раздел "О себе":
Навыки:
Опыт работы:
Проекты (для Junior):
ATS-оптимизация:
Проверка ценности:
Финальный тест: Правило 30 секунд
Дайте резюме почитать другу на 30 секунд. Спросите:
Если друг не может ответить — резюме нужно доработать.
Нет. Указывайте только те технологии, с которыми готовы работать и о которых можете говорить на собеседовании. Если вы один раз делали pet-проект на TensorFlow 3 года назад и с тех пор не использовали — не указывайте. Это создаст ложные ожидания и может привести к неудобным вопросам на интервью.
Правило: Включайте технологию, если можете на ней решить практическую задачу средней сложности без длительной подготовки.
Укажите аутсорсинговую компанию как работодателя, а затем перечислите проекты для разных клиентов:
ML Engineer
IT Аутсорсинговая компания, Москва — 01.2022 — 12.2024
Разработка ML-решений для клиентов из e-commerce, fintech и healthcare.
Проект для ритейлера (6 месяцев):
- Разработал систему динамического ценообразования...
Проект для банка (4 месяца):
- Внедрил модель скоринга заемщиков...
Проект для медицинского стартапа (5 месяцев):
- Создал модель сегментации опухолей на МРТ-снимках...
Такой подход показывает разнообразие опыта и адаптивность.
Если перерыв меньше 3-4 месяцев — можно не объяснять. Если больше:
Честно и кратко укажите причину:
Карьерный перерыв — 06.2023 — 12.2023
Изучение LLM и MLOps: прошел 3 специализации на Coursera (Deep Learning, MLOps,
AWS ML Specialty), разработал 2 проекта с LangChain и GPT-4 API (ссылки на GitHub)
или
Релокация и адаптация — 03.2024 — 07.2024
Переезд в новую страну, легализация документов. В этот период работал над
pet-проектом по анализу временных рядов (GitHub)
Ключ: Показать, что время не было потеряно зря — вы учились, делали проекты, развивались.
Мнение большинства рекрутеров: Нет, не стоит указывать в самом резюме. Причины:
Исключение: Если вакансия явно требует указать желаемую зарплату, можно добавить строку в контактах:
Зарплатные ожидания: от 250 000 руб./месяц (обсуждаемо в зависимости от условий)
Стратегия усиления резюме для Junior:
Пример формулировки:
Pet-проект: ML-модель для предсказания цен недвижимости
- Собрал данные с сайтов объявлений (парсинг, 20k объектов)
- Провел EDA, feature engineering, сравнил 5 моделей регрессии
- Лучший результат: gradient boosting с RMSE $12k (топ 5% на публичном бенчмарке)
- Задеплоил как веб-приложение на Streamlit + Docker
Такой проект показывает полный цикл и практические навыки.
Для Research Engineer / Applied Scientist: Да, это важно. Создайте отдельный раздел "Публикации":
ПУБЛИКАЦИИ
- Petrov I., Ivanov S. "Efficient Training of Large-Scale Recommender Systems
with Neural Collaborative Filtering" // ICML 2024 Workshop on Recommender Systems
- Петров И. В. "Метод оптимизации гиперпараметров нейросетей на основе
байесовского подхода" // Вестник МГУ. Серия 15: Вычислительная математика
и кибернетика. 2023. №2. С. 45-52
Для ML Engineer в продукте: Можно указать, но не делать акцент. Работодатели больше ценят практический опыт деплоя моделей, чем теоретические исследования.
Рекомендация:
Резюме, которое обновляется регулярно, всегда готово к неожиданным возможностям и содержит точные данные.
Резюме ML-разработчика — это не формальность, а ваш главный инструмент для получения интервью в желаемой компании. В условиях высокой конкуренции (87 кандидатов на одну вакансию) выигрывают те, кто умеет правильно упаковать свою экспертизу.
Ключевые принципы эффективного ML-резюме:
Используйте это руководство как чек-лист при создании или обновлении резюме. Инвестируйте время в качественную подготовку документа — это сэкономит месяцы поиска работы и откроет двери в компании вашей мечты.
Ваше резюме — это проект, который требует такого же внимания к деталям, как и ML-модель: правильная архитектура, оптимизация под целевую метрику, итеративные улучшения. Примените свои аналитические навыки к собственной карьере, и результат не заставит себя ждать.
Следующий шаг: Откройте свое текущее резюме и пройдите по чек-листу из этой статьи. Найдите 3-5 мест, где можно усилить формулировки, добавить метрики или переструктурировать информацию. Внесите изменения прямо сейчас — и уже завтра ваше резюме будет работать на вас эффективнее.

1000+ офферов получено
Quick Offer улучшит ваше резюме, подберёт лучшие вакансии и откликнется за вас. Результат — в 3 раза больше приглашений на собеседования и никакой рутины!