Как составить резюме DevOps-инженера: полное руководство с примерами и метриками
devops разработчик - готовый пример резюме для профессии и руководство по составлению с советами бесплатно.
devops разработчик
- +7 (914) 333-23-33
- ivanov.devops-razrabotchik@gmail.com
- ivanov-ivan.ru
- Проживает: Москва, Россия
- Гражданство: Россия
- Разрешение на работу: есть, Россия
- Не готов к переезду, не готов к командировкам
Желаемая должность и зарплата
devops разработчик
- Специализации:
- - devops разработчик;
- Занятость: полная занятость
- График работы: полный день
- Время в пути до работы: не имеет значения
Резюме DevOps-инженера — это не просто перечисление технологий, которыми вы владеете. Это техническая спецификация вашей ценности для бизнеса. Рекрутеры ежедневно просматривают десятки резюме, где кандидаты перечисляют Kubernetes, Docker, CI/CD и AWS. Но что отличает документ, который попадает в короткий список, от того, который отправляется в архив?
Ответ прост: измеримое влияние на бизнес-процессы. Работодатели ищут не того, кто знает Terraform, а того, кто с помощью Terraform сократил время деплоя с 45 минут до 8 или снизил инфраструктурные расходы на 35%.
Я проанализировал более 50 вакансий DevOps-инженеров в 2026 году и выявил главный тренд: компании хотят видеть конкретные метрики — uptime сервисов, скорость развертывания, экономию бюджета. При этом требования сильно различаются в зависимости от уровня позиции.
Junior должен показать способность быстро учиться и применять знания на практике через pet-проекты и лабораторные работы. Middle — продемонстрировать опыт решения реальных проблем с измеримым результатом. Senior и Lead — доказать умение проектировать архитектуру, влиять на процессы всей компании и принимать стратегические решения.
В этом руководстве вы получите пошаговый план создания резюме, которое пройдет ATS-системы и заинтересует рекрутера. Я покажу готовые формулы, шаблоны для разных уровней и конкретные примеры с метриками. После прочтения у вас будет резюме, которое четко отвечает на вопрос: «Почему именно я решу проблемы этой компании?»
Заголовок и контактная информация: первое впечатление за 3 секунды
Заголовок резюме — это первое, что видит рекрутер. У вас есть 3 секунды, чтобы его зацепить или потерять навсегда.
Как правильно назвать должность
Название должности должно быть конкретным, узнаваемым и соответствовать рынку. Вот работающие формулы:
Для Junior (0-2 года опыта):
- Junior DevOps Engineer
- DevOps Engineer
- Cloud Infrastructure Engineer
Для Middle (2-5 лет):
- DevOps Engineer
- Site Reliability Engineer (SRE)
- Cloud DevOps Engineer
- Platform Engineer
Для Senior/Lead (5+ лет):
- Senior DevOps Engineer
- Lead DevOps Engineer
- DevOps Architect
- Principal SRE
Совет эксперта: Если в вакансии указано "Site Reliability Engineer", используйте именно это название в своем резюме, даже если ваша текущая должность — "DevOps Engineer". ATS-системы ищут точное совпадение ключевых слов, и это может быть решающим фактором.
Чего избегать:
- Размытых формулировок: "IT-специалист", "Системный администратор с DevOps"
- Слишком широких: "Программист"
- Без указания уровня: просто "DevOps" (неясно, Junior вы или Senior)
- Креативных названий: "DevOps-ниндзя", "Облачный волшебник"
Контактная информация: что обязательно, а что лишнее
Обязательные элементы:
- Полное имя (без отчества, если работаете с международными компаниями)
- Телефон (в формате +7 XXX XXX-XX-XX)
- Email (профессиональный: имя.фамилия@gmail.com)
- Город проживания (без полного адреса)
- GitHub или GitLab профиль — критически важно для DevOps
Необязательные, но полезные:
- Telegram (если активно используете для работы)
- LinkedIn профиль
- Личный блог или портфолио с техническими статьями
Не указывайте:
- Полный домашний адрес
- Дату рождения (может стать основой для дискриминации)
- Семейное положение
- Фотографию (если только это не требование вакансии)
Почему GitHub-профиль — ваше конкурентное преимущество
Для DevOps-инженера ссылка на GitHub — это не опция, а обязательный элемент резюме. Работодатели хотят видеть:
- Ваши pet-проекты с Infrastructure as Code
- Вклад в open source проекты
- Качество кода и документации
- Активность и регулярность коммитов
Что должно быть в вашем GitHub:
- Закрепленные репозитории с наиболее показательными проектами
- Подробные README с описанием задачи, технологий и результатов
- Terraform/Ansible скрипты с комментариями
- Docker Compose файлы для развертывания приложений
- CI/CD пайплайны в примерах проектов
Совет эксперта: Если у вас мало активности на GitHub, создайте 2-3 качественных демо-проекта прямо сейчас. Например: развертывание мониторинга Prometheus+Grafana через Terraform, настройку CI/CD для Node.js приложения с тестами, или инфраструктуру для WordPress на Kubernetes. Даже учебные проекты с качественной документацией произведут впечатление.
Раздел "О себе": как зацепить за 30 секунд
Раздел Summary или "О себе" — это ваша elevator pitch. Рекрутер тратит на него 20-30 секунд, и за это время вы должны ответить на три вопроса:
- Кто вы и каков ваш уровень?
- Какую ценность приносите?
- Почему вы подходите именно для этой позиции?
Ваше резюме может быть лучше
Сравните, как ИИ-резюмейкер Quick Offer превращает резюме с hh.ru в профессиональное

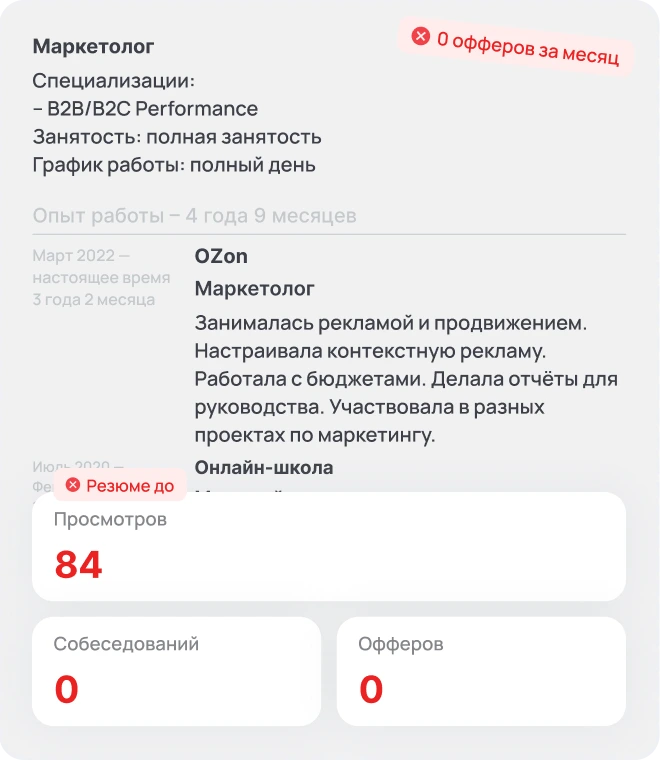
Структура эффективного Summary
Работающая формула состоит из 3-4 предложений:
[Уровень + опыт] + [Ключевые технологии] + [Главное достижение с метрикой] + [Что ищете]
Шаблоны с примерами для разных уровней
Пример 1: Junior DevOps Engineer
Плохо:
Начинающий DevOps-инженер. Знаю Docker, Kubernetes, CI/CD.
Быстро обучаюсь. Ищу работу в крупной компании.
Хорошо:
Junior DevOps Engineer с опытом реализации 5+ учебных и pet-проектов
по автоматизации развертывания. Владею Docker, Kubernetes, GitLab CI
и Terraform. В последнем проекте настроил полный CI/CD пайплайн для
микросервисного приложения с автотестами, что сократило время
развертывания новых версий с ручных 2 часов до автоматических 15 минут.
Ищу позицию Junior DevOps для роста в направлении Platform Engineering.
Почему это работает:
- Конкретный уровень и область опыта
- Перечислены актуальные технологии
- Есть измеримое достижение (2 часа → 15 минут)
- Понятно, чего хотите
Пример 2: Middle DevOps Engineer
Плохо:
Опытный DevOps-инженер. Занимаюсь автоматизацией и поддержкой
инфраструктуры. Работал с облаками и контейнерами.
Хорошо:
DevOps Engineer с 3+ годами опыта построения CI/CD процессов и управления
облачной инфраструктурой на AWS. Специализируюсь на контейнеризации
(Docker, Kubernetes) и Infrastructure as Code (Terraform, Ansible).
В текущем проекте мигрировал 12 микросервисов в Kubernetes, внедрил
GitOps-подход с ArgoCD и настроил мониторинг на Prometheus/Grafana,
что повысило uptime с 98.5% до 99.7% и сократило MTTR с 1.5 часов до 20 минут.
Ищу возможность работать над высоконагруженными системами в продуктовой компании.
Ключевые отличия:
- Конкретный срок опыта (3+ года)
- Названа специализация
- Два измеримых достижения с метриками (uptime, MTTR)
- Указан тип желаемой компании
Пример 3: Senior/Lead DevOps Engineer
Плохо:
Старший DevOps-инженер с большим опытом. Руководил командами.
Работал с разными технологиями и проектами.
Хорошо:
Senior DevOps Engineer с 6+ годами опыта проектирования и масштабирования
облачной инфраструктуры для продуктов с аудиторией 1M+ пользователей.
Руководил командой из 4 DevOps-инженеров. Спроектировал и реализовал
миграцию монолитного приложения в микросервисную архитектуру на AWS EKS
с применением Terraform, Service Mesh (Istio) и GitOps практик. Результат:
сокращение времени релизов с 2 недель до 3 дней, повышение доступности
до 99.95% и экономия инфраструктурных затрат на $42K/год. Ищу Lead DevOps
позицию для построения Platform Engineering культуры.
Что делает этот пример сильным:
- Масштаб влияния (1M+ пользователей)
- Опыт руководства
- Архитектурное решение (миграция в микросервисы)
- Три конкретные метрики (время, uptime, экономия)
- Стратегическая цель (Platform Engineering)
Ключевые слова для прохождения ATS
ATS (Applicant Tracking System) — это роботы, которые сканируют резюме перед тем, как их увидит человек. Чтобы пройти автоматический отбор, включите в раздел "О себе" ключевые слова из вакансии:
Обязательные технологии для 2026:
- Контейнеризация: Docker, Kubernetes, Helm
- CI/CD: GitLab CI, Jenkins, GitHub Actions, ArgoCD
- IaC: Terraform, Ansible, CloudFormation
- Облака: AWS, Google Cloud, Azure
- Мониторинг: Prometheus, Grafana, ELK Stack
- Языки: Python, Bash, Go
Актуальные тренды 2025:
- GitOps (FluxCD, ArgoCD)
- Platform Engineering
- Service Mesh (Istio, Linkerd)
- FinOps практики
- Policy as Code (OPA)
- OpenTelemetry
Совет эксперта: Откройте 5-7 интересных вам вакансий и выпишите технологии, которые упоминаются чаще всего. Именно эти ключевые слова должны быть в вашем Summary. Но не превращайте раздел в бессмысленный список — органично вплетайте термины в контекст достижений.
Технические навыки: как составить убедительный список
Раздел с техническими навыками — один из самых важных для DevOps-инженера. Рекрутеры и ATS-системы в первую очередь сканируют именно его. Но есть тонкая грань между исчерпывающим списком и хаотичной "простыней" технологий.
Как правильно группировать навыки
Не сваливайте все технологии в одну кучу. Структурируйте по категориям — так рекрутер за 10 секунд поймет вашу экспертизу.
Базовая структура для DevOps:
Контейнеризация и оркестрация:
Docker, Kubernetes, Helm, Docker Compose
CI/CD:
GitLab CI/CD, Jenkins, GitHub Actions, ArgoCD, FluxCD
Infrastructure as Code:
Terraform, Ansible, CloudFormation, Packer
Облачные платформы:
AWS (EC2, ECS, EKS, S3, RDS, Lambda), Google Cloud Platform, Azure
Мониторинг и логирование:
Prometheus, Grafana, ELK Stack (Elasticsearch, Logstash, Kibana),
Datadog, Zabbix
Языки программирования и скриптинг:
Python, Bash, Go, PowerShell
Системы контроля версий:
Git, GitHub, GitLab, Bitbucket
Операционные системы:
Linux (Ubuntu, CentOS, RHEL), Windows Server
Базы данных:
PostgreSQL, MySQL, MongoDB, Redis
Как указывать уровень владения
Есть два подхода: с явным указанием уровня и без него.
Вариант 1: С указанием уровня
Используйте только если уверены в градации. Шкала:
- Expert/Advanced — используете ежедневно 2+ года, можете решать сложные проблемы и обучать других
- Intermediate/Proficient — работаете с технологией регулярно, решаете типовые задачи самостоятельно
- Basic/Beginner — изучали, делали учебные проекты, нужна помощь в сложных случаях
Пример:
Контейнеризация:
- Docker (Advanced) — 3 года коммерческого опыта
- Kubernetes (Intermediate) — 1.5 года, управление кластерами до 50 подов
- Helm (Basic) — использовал для деплоя готовых чартов
Вариант 2: Без явного указания (рекомендуется для Middle+)
Просто группируйте технологии по категориям. Сам факт включения в резюме означает, что вы готовы работать с этим инструментом.
Совет эксперта: Для Junior указание уровня полезно — оно показывает честность и понимание своих границ. Для Senior и Lead лучше обойтись без градации: от вас ожидают глубокой экспертизы во всем, что вы указали.
Что обязательно добавить в 2026 году
Технологический ландшафт DevOps постоянно эволюционирует. Вот что сейчас на пике спроса:
Must-have для любого уровня:
- Kubernetes (если его нет — это красный флаг)
- Один из облачных провайдеров (AWS лидирует)
- Terraform (стандарт де-факто для IaC)
- Git и GitOps подход
- Базовый мониторинг (Prometheus + Grafana)
Nice-to-have для Middle:
- Service Mesh (Istio или Linkerd)
- Продвинутые практики CI/CD (Blue-Green, Canary deployments)
- Secrets management (Vault, AWS Secrets Manager)
- Container security (Trivy, Falco)
Expected для Senior/Lead:
- Platform Engineering практики
- FinOps и cost optimization
- Policy as Code (Open Policy Agent)
- Observability (OpenTelemetry, distributed tracing)
- Multi-cloud или hybrid cloud опыт
Частые ошибки: "простыня" технологий
Ошибка №1: Перечисление всего, что когда-либо видели
❌ Плохо:
AWS, Azure, GCP, Docker, Kubernetes, OpenShift, Nomad, Jenkins,
GitLab CI, GitHub Actions, CircleCI, TeamCity, Bamboo, Terraform,
Ansible, Puppet, Chef, SaltStack, Python, Java, C++, Ruby, Go,
Rust, JavaScript...
Это создает впечатление, что вы либо пытаетесь обмануть, либо разбрасываетесь. Рекрутер не поверит, что вы одинаково хорошо знаете 30 технологий.
✅ Хорошо:
Контейнеризация: Docker, Kubernetes, Helm
CI/CD: GitLab CI/CD, Jenkins
IaC: Terraform, Ansible
Cloud: AWS (EC2, EKS, S3, RDS, Lambda)
Мониторинг: Prometheus, Grafana, ELK Stack
Языки: Python, Bash
Ошибка №2: Устаревшие технологии без контекста
Если указываете технологию, которой 10+ лет (например, SVN вместо Git), объясните контекст:
Системы контроля версий: Git (основное), SVN (поддержка legacy-проектов)
Ошибка №3: Смешивание разных уровней абстракции
❌ Плохо:
AWS, EC2, S3, Cloud Computing, Виртуализация, Amazon
EC2 и S3 — это сервисы AWS. "Cloud Computing" — это парадигма, а не инструмент. "Amazon" — это компания. Не создавайте путаницу.
✅ Хорошо:
Облачные платформы: AWS (EC2, S3, EKS, RDS, Lambda, CloudFormation)
Опыт работы: превращаем задачи в достижения с метриками
Раздел с опытом работы — сердце вашего резюме. Здесь вы либо убеждаете работодателя в своей ценности, либо теряете его внимание. Разница между средним и выдающимся резюме — в умении трансформировать рутинные обязанности в измеримые достижения.
Формула описания: контекст + действие + результат
Каждое достижение должно отвечать на три вопроса:
- Контекст: Какая была проблема или задача?
- Действие: Что конкретно вы сделали?
- Результат: Какой измеримый эффект это дало?
Базовая формула:
[Глагол действия] + [что сделали] + [с какими технологиями] +
[измеримый результат с метриками]
Мы берём поиск работы на себя
Подбираем лучшие вакансии и откликаемся за вас. До 100 автооткликов в день.

10 примеров с метриками для разных задач
1. Настройка CI/CD
❌ Было: Настраивал CI/CD пайплайны
✅ Стало: Внедрил GitOps-подход с ArgoCD для автоматического деплоя 15 микросервисов, сократив время релиза с 45 минут до 8 минут и снизив количество ошибок при развертывании на 73%
Метрики: время, количество сервисов, процент снижения ошибок
2. Миграция в облако
❌ Было: Переносил приложения в AWS
✅ Стало: Спроектировал и реализовал миграцию монолитного приложения (5 компонентов, 50K строк кода) в AWS с использованием ECS, Terraform и Application Load Balancer, обеспечив горизонтальное масштабирование и сократив расходы на инфраструктуру на $18K/год (35%)
Метрики: масштаб приложения, технологии, экономия в деньгах и процентах
3. Мониторинг и алертинг
❌ Было: Занимался мониторингом инфраструктуры
✅ Стало: Построил комплексную систему мониторинга на базе Prometheus и Grafana с 200+ метриками для 12 микросервисов, создал 15 дашбордов и настроил алертинг в Slack, что позволило выявлять инциденты на 40% быстрее и снизить MTTR с 2 часов до 25 минут
Метрики: количество метрик, дашбордов, процент улучшения, время восстановления
4. Автоматизация рутинных задач
❌ Было: Автоматизировал процессы с помощью скриптов
✅ Стало: Разработал набор Python и Bash скриптов для автоматизации резервного копирования 8 баз данных PostgreSQL, настройки новых серверов и ротации логов, сократив время на рутинные операции с 15 до 2 часов в неделю (экономия 52 часов/год)
Метрики: количество объектов, время до и после, годовая экономия
5. Масштабирование инфраструктуры
❌ Было: Настраивал автомасштабирование
✅ Стало: Внедрил автомасштабирование Kubernetes кластера на базе HPA и Cluster Autoscaler, что позволило выдерживать пиковые нагрузки до 10K RPS (рост в 3 раза) без деградации производительности и оптимизировать использование ресурсов (снижение idle capacity с 40% до 15%)
Метрики: нагрузка (RPS), кратность роста, процент оптимизации
6. Улучшение безопасности
❌ Было: Работал над повышением безопасности
✅ Стало: Внедрил автоматическое сканирование Docker образов с помощью Trivy в CI/CD пайплайн, настроил Vault для управления секретами и применил Network Policies в Kubernetes, устранив 27 критических уязвимостей и приведя инфраструктуру в соответствие с требованиями SOC 2
Метрики: количество устраненных уязвимостей, compliance-стандарт
7. Оптимизация затрат
❌ Было: Оптимизировал облачную инфраструктуру
✅ Стало: Провел FinOps-аудит AWS инфраструктуры, перевел 12 EC2-инстансов на Reserved Instances, настроил lifecycle policies для S3 и оптимизировал размеры RDS, сократив месячные расходы с $8,500 до $5,200 (экономия $39,600/год)
Метрики: количество объектов, затраты до и после, годовая экономия
8. Disaster Recovery
❌ Было: Настраивал бэкапы и восстановление
✅ Стало: Спроектировал и внедрил disaster recovery стратегию с RPO 15 минут и RTO 1 час для критичных сервисов, автоматизировал бэкапы в S3 с помощью Velero и провел 3 drill-теста, подтвердив работоспособность процедур восстановления
Метрики: RPO/RTO, количество тестов, покрытие сервисов
9. Infrastructure as Code
❌ Было: Описывал инфраструктуру как код
✅ Стало: Перевел всю облачную инфраструктуру (35 ресурсов AWS) в Terraform код, организовал модульную структуру, настроил Terraform Cloud для state management и внедрил процесс code review для изменений инфраструктуры, исключив ручные правки и конфигурационный дрейф
Метрики: количество ресурсов, результат (zero manual changes)
10. Обучение команды
❌ Было: Помогал коллегам с DevOps практиками
✅ Стало: Разработал и провел серию из 5 воркшопов по Kubernetes, Helm и GitOps для 3 команд разработки (18 человек), создал внутреннюю документацию с best practices, что ускорило adoption Kubernetes на 40% и снизило количество инцидентов, связанных с некорректной конфигурацией, на 60%
Метрики: количество воркшопов, участников, процент улучшений
Как описывать опыт Junior без коммерческих проектов
Отсутствие коммерческого опыта — не приговор. Работодатели понимают, что джуниорам нужно с чего-то начинать. Главное — показать, что вы способны применять знания на практике.
Что можно и нужно включать:
Pet-проекты
Создайте 2-3 реальных проекта, которые демонстрируют ваши навыки:
Personal Projects
Автоматизированный деплой веб-приложения с мониторингом
• Разработал инфраструктуру для развертывания full-stack приложения
(React + Node.js + PostgreSQL) в AWS с использованием Terraform и Docker
• Настроил CI/CD пайплайн в GitHub Actions с автотестами и автоматическим
деплоем в ECS
• Внедрил мониторинг с Prometheus и Grafana, создал 5 дашбордов для
отслеживания метрик приложения и инфраструктуры
• Технологии: AWS (ECS, RDS, ALB), Terraform, Docker, GitHub Actions,
Prometheus, Grafana
• Результат: полностью автоматизированный процесс от коммита до продакшена
за 12 минут
Open Source вклад
Если делали pull request'ы в open source проекты:
Open Source Contributions
Kubernetes Community (github.com/kubernetes)
• Исправил 2 бага в документации по StatefulSets и NetworkPolicies
• Pull requests были приняты maintainers и включены в официальную документацию
• Получил практический опыт работы с крупной кодовой базой и процессом
code review
Лабораторные работы и сертификационные проекты
Если проходили курсы с практическими заданиями:
Практический опыт
Проект в рамках курса "AWS DevOps Engineer" (Coursera)
• Спроектировал и развернул отказоустойчивую инфраструктуру для веб-приложения
в AWS в 3 availability zones
• Настроил Auto Scaling, Load Balancer, RDS с Multi-AZ, CloudWatch алертинг
• Автоматизировал создание инфраструктуры через CloudFormation (200+ строк IaC)
• Результат: приложение выдерживает отказ целой зоны без downtime,
автоматически масштабируется под нагрузкой от 1 до 10 инстансов
Совет эксперта: Не пишите просто "сделал pet-проект". Описывайте его как реальную коммерческую задачу: какую проблему решали, какие технологии применили, какой результат получили. Даже если это учебный проект, покажите его с точки зрения бизнес-ценности.
Кейсы: 3 примера готовых резюме
Теория без практики бесполезна. Давайте посмотрим на три полноценных примера резюме для разных уровней — от джуниора до лида.
Кейс 1: Junior DevOps Engineer (после курсов)
Алексей Иванов
Junior DevOps Engineer
Телефон: +7 999 123-45-67
Email: aleksey.ivanov.devops@gmail.com
GitHub: github.com/aivanov-devops
Telegram: @aivanov_devops
Город: Москва
О себе
Junior DevOps Engineer с опытом реализации 6 учебных и pet-проектов
по автоматизации развертывания и управлению инфраструктурой. Прошел
профессиональную переподготовку по направлению Cloud & DevOps
(400 часов практики). Владею Docker, Kubernetes, GitLab CI, Terraform
и AWS. В финальном проекте создал полный CI/CD пайплайн для микросервисного
приложения с автотестами, мониторингом и автоматическим развертыванием в AWS,
сократив время деплоя с ручных 2 часов до автоматических 15 минут.
Ищу позицию Junior DevOps в продуктовой компании для роста в направлении
Platform Engineering.
Технические навыки
Контейнеризация и оркестрация:
Docker, Kubernetes, Helm, Docker Compose
CI/CD:
GitLab CI/CD, GitHub Actions
Infrastructure as Code:
Terraform, Ansible
Облачные платформы:
AWS (EC2, ECS, S3, RDS, Lambda, CloudFormation)
Мониторинг:
Prometheus, Grafana, основы ELK Stack
Языки программирования:
Python, Bash
Системы контроля версий:
Git, GitHub, GitLab
Операционные системы:
Linux (Ubuntu, CentOS)
Базы данных:
PostgreSQL, MySQL, Redis (базовый уровень)
Практический опыт
Pet-проект: Полный цикл DevOps для e-commerce приложения
Сентябрь 2024 – Ноябрь 2024
• Спроектировал и развернул инфраструктуру для full-stack приложения
(React + Node.js + PostgreSQL) в AWS с использованием Terraform и Docker
• Настроил CI/CD пайплайн в GitLab CI с 3 стейджами (build, test, deploy),
включая unit-тесты, security-сканирование и автоматический деплой в ECS
• Внедрил мониторинг на базе Prometheus и Grafana с 25 метриками, создал
5 дашбордов для отслеживания здоровья приложения
• Настроил автомасштабирование ECS-сервисов и Application Load Balancer
для распределения нагрузки
• Результат: полностью автоматизированный процесс от коммита до продакшена
за 15 минут, приложение выдерживает нагрузку до 500 RPS
• Ссылка на репозиторий: github.com/aivanov-devops/ecommerce-infra
Проект в рамках обучения: Kubernetes кластер для микросервисов
Июль 2024 – Август 2024
• Развернул Kubernetes кластер на 3 нодах с помощью kubeadm
• Мигрировал 5 микросервисов из docker-compose в Kubernetes с использованием
Helm charts
• Настроил Ingress-контроллер Nginx, создал манифесты для Deployments,
Services, ConfigMaps и Secrets
• Внедрил Health Checks (liveness/readiness probes) для всех сервисов
• Результат: отказоустойчивая система с автоматическим перезапуском
упавших подов, zero downtime при обновлениях через rolling updates
Open Source Contributions
Terraform AWS Modules (github.com/terraform-aws-modules)
• Внес улучшения в документацию модуля terraform-aws-eks
• Pull request был принят maintainers (200+ stars на изменение)
Образование и сертификация
AWS Certified Cloud Practitioner — Amazon Web Services, 2024
HashiCorp Terraform Associate — HashiCorp, 2024
Профессиональная переподготовка "Cloud & DevOps Engineer"
Skillbox, 2024 (400 часов практики)
Бакалавр, Прикладная информатика
МГУ, 2020-2024
Дополнительная информация
Языки: Русский (родной), Английский (B2 — чтение технической документации)
Почему это резюме работает:
- Честно указан уровень Junior, но показана серьезная подготовка
- Pet-проекты описаны как коммерческие задачи с метриками
- Есть ссылки на GitHub для проверки
- Показан вклад в open source (доказательство способности работать в команде)
- Актуальные сертификации подтверждают знания
Кейс 2: Middle DevOps Engineer (3 года опыта)
Мария Петрова
DevOps Engineer
+7 999 876-54-32 | maria.petrova.sre@gmail.com | github.com/mpetrova-ops
LinkedIn: linkedin.com/in/mpetrova-devops | Санкт-Петербург
О себе
DevOps Engineer с 3+ годами опыта построения CI/CD процессов, управления
облачной инфраструктурой и внедрения SRE-практик. Специализируюсь на
контейнеризации (Docker, Kubernetes), Infrastructure as Code (Terraform,
Ansible) и мониторинге высоконагруженных систем. В текущем проекте мигрировал
12 микросервисов в Kubernetes, внедрил GitOps-подход с ArgoCD и построил
комплексный мониторинг, что повысило uptime с 98.5% до 99.7% и сократил MTTR
с 1.5 часов до 20 минут. Ищу возможность работать над высоконагруженными
системами с аудиторией 1M+ пользователей в продуктовой компании.
Технические навыки
Контейнеризация и оркестрация: Docker, Kubernetes, Helm, Kustomize
CI/CD: GitLab CI/CD, ArgoCD, GitHub Actions, Jenkins
IaC: Terraform, Ansible, CloudFormation
Облака: AWS (EC2, ECS, EKS, S3, RDS, Lambda, CloudWatch), Google Cloud (GKE, GCS)
Мониторинг: Prometheus, Grafana, ELK Stack, Datadog, Jaeger
Языки: Python, Bash, Go (базовый)
Service Mesh: Istio
Secrets Management: HashiCorp Vault
Security: Trivy, Falco, OPA
Опыт работы
DevOps Engineer | FinTech Startup "PayWave" | Санкт-Петербург
Июль 2022 – Настоящее время
Проект: Миграция в Kubernetes и внедрение GitOps
• Спроектировал и выполнил миграцию 12 микросервисов платежной системы
из EC2 в AWS EKS, спроектировал Helm charts с учетом best practices
(resources, probes, security contexts)
• Внедрил GitOps-подход с ArgoCD для автоматической синхронизации состояния
кластера с Git, сократив время деплоя с 35 до 7 минут и снизив количество
ошибок релизов на 68%
• Настроил Istio Service Mesh для управления трафиком между микросервисами,
внедрил mutual TLS и реализовал canary deployments для безопасных релизов
• Результат: uptime повысился с 98.5% до 99.7%, zero-downtime deployments,
прохождение PCI DSS аудита по требованиям к инфраструктуре
Проект: Мониторинг и обсервабельность
• Построил комплексную систему мониторинга на Prometheus и Grafana с 250+
метриками (RED метрики для всех сервисов, инфраструктурные метрики,
бизнес-метрики)
• Создал 18 дашбордов и настроил 35 алертов в PagerDuty с разделением
по severity (critical/warning/info)
• Внедрил distributed tracing с Jaeger для отладки латентности между
микросервисами
• Результат: время выявления инцидентов сократилось на 55%, MTTR снизился
с 1.5 часов до 20 минут, количество false-positive алертов уменьшилось на 40%
Проект: Оптимизация затрат и FinOps
• Провел аудит AWS инфраструктуры, выявил 8 overprovisioned инстансов
и 120 GB неиспользуемых EBS volumes
• Внедрил Kubernetes HPA и Cluster Autoscaler, оптимизировал resource
requests/limits для всех подов
• Настроил S3 Lifecycle policies и перевел 40% EC2 инстансов на Reserved Instances
• Результат: снижение месячных расходов на AWS с $12,300 до $7,800
(экономия $54,000/год или 37%)
Junior DevOps Engineer | E-commerce "ShopHub" | Санкт-Петербург
Март 2021 – Июнь 2022
• Автоматизировал процесс сборки и деплоя 8 микросервисов через GitLab CI/CD,
сократив время релиза с 2 часов до 25 минут
• Перевел инфраструктуру в Infrastructure as Code с использованием Terraform
(55 ресурсов AWS), организовал модульную структуру и remote state в S3
• Настроил автоматическое резервное копирование 5 баз данных PostgreSQL
и MySQL с retention policy 30 дней
• Разработал набор Bash и Python скриптов для автоматизации рутинных задач
(ротация логов, обновление SSL-сертификатов, health checks)
• Результат: сокращение времени на рутинные операции с 12 до 3 часов в неделю
Образование и сертификация
Certified Kubernetes Administrator (CKA) — Cloud Native Computing Foundation, 2023
AWS Certified Solutions Architect – Associate — Amazon Web Services, 2022
HashiCorp Certified: Terraform Associate — HashiCorp, 2022
Бакалавр, Информационные системы и технологии
СПбГУ, 2017-2021
Дополнительная информация
Языки: Русский (родной), Английский (B2+)
Публикации: 3 статьи на Habr по темам Kubernetes и мониторинга (5K+ просмотров)
Что делает это резюме сильным:
- Конкретные метрики во всех проектах (uptime, время, экономия)
- Показан рост от Junior до Middle
- Актуальная специализация (FinTech с PCI DSS)
- Сертификации подтверждают экспертизу (CKA — золотой стандарт)
- Дополнительная активность (статьи на Habr)
Создадим сопроводительные, которые приносят результат
AI создаст 3 письма под ваше резюме и подберёт лучшее под каждую вакансию.

Кейс 3: Senior/Lead DevOps Engineer
Дмитрий Соколов
Senior DevOps Engineer / DevOps Architect
+7 999 555-11-22 | dmitry.sokolov.lead@gmail.com | github.com/dsokolov-infra
LinkedIn: linkedin.com/in/dsokolov-devops | Москва
Summary
Senior DevOps Engineer с 7+ годами опыта проектирования и масштабирования
облачной инфраструктуры для высоконагруженных систем с аудиторией 5M+
пользователей. Руководил командой из 5 DevOps/SRE-инженеров. Специализируюсь
на Platform Engineering, multi-cloud архитектурах и внедрении SRE-культуры.
Спроектировал и реализовал миграцию монолитной системы в микросервисную
архитектуру на AWS EKS с применением Terraform, Service Mesh и GitOps практик.
Результаты: сокращение времени релизов с 2 недель до 2 дней (10x improvement),
повышение доступности до 99.95%, экономия инфраструктурных затрат на $180K/год.
Ищу Lead DevOps/Platform Engineering позицию для построения Internal Developer
Platform и SRE-культуры.
Core Competencies
Leadership: Управление командой DevOps/SRE (5 человек), менторинг, процессы
Architecture: Design высоконагруженных систем, multi-cloud, disaster recovery
Automation: Terraform, Ansible, Python, Go
Containers: Kubernetes (CKA certified), Docker, Helm, Service Mesh (Istio, Linkerd)
Cloud: AWS (Solutions Architect Professional), Google Cloud, Azure (multi-cloud)
CI/CD: GitLab CI, ArgoCD, FluxCD, Jenkins, Spinnaker
Observability: Prometheus, Grafana, ELK, OpenTelemetry, Datadog
Security: Zero Trust, Policy as Code (OPA), secrets management, compliance
FinOps: Cost optimization, FinOps practices, budget management
Professional Experience
Lead DevOps Engineer / Team Lead | EdTech Platform "LearnPro" | Москва
Январь 2021 – Настоящее время
Руководство командой и построение Platform Engineering культуры
• Управляю командой из 5 DevOps/SRE-инженеров (4 Middle, 1 Junior),
провожу 1-on-1, performance reviews, развиваю инженеров
• Построил Internal Developer Platform на базе Kubernetes, ArgoCD и Backstage,
предоставив командам разработки self-service для деплоя и мониторинга
• Внедрил SRE-практики: SLO/SLI метрики, error budget, postmortem culture,
on-call ротации с эскалацией
• Результат: time-to-production для новых сервисов сократился с 3 недель
до 2 дней, NPS команд разработки вырос с 6 до 8.5, снижение burnout
в команде DevOps (from 60% to 20% по internal surveys)
Проект: Миграция в микросервисную архитектуру и multi-cloud
• Спроектировал и возглавил миграцию монолитного LMS-приложения (300K LOC)
в 25 микросервисов на AWS EKS и Google Cloud GKE (multi-cloud для DR)
• Разработал Terraform-модули для создания стандартизированной инфраструктуры
(networking, Kubernetes clusters, databases, monitoring), покрывающие 200+
AWS/GCP ресурсов
• Внедрил Istio Service Mesh для управления трафиком, security policies
(mutual TLS, authorization) и observability (distributed tracing)
• Построил GitOps-процесс с ArgoCD и ApplicationSets для управления 25
приложениями в 4 окружениях (dev, staging, prod, DR)
• Результат: релизы с 2 недель до 2 дней (10x), deployment frequency вырос
с 2/месяц до 50/месяц, uptime повысился до 99.95% (SLA), успешное прохождение
disaster recovery drill с RTO 2 часа
Проект: Observability и AIOps
• Спроектировал комплексную observability-систему на базе OpenTelemetry,
Prometheus, Grafana, ELK и Jaeger для 25 микросервисов
• Создал 40+ Grafana дашбордов (RED метрики, SLI dashboards, business metrics),
настроил 60+ алертов с разделением по severity и teams
• Внедрил автоматическое обнаружение аномалий и predictive alerting с помощью
Datadog ML-моделей
• Результат: MTTD сократился с 25 минут до 3 минут (8x faster), MTTR снизился
с 40 минут до 12 минут, 70% инцидентов выявляются до impact на пользователей
Проект: FinOps и cost optimization
• Внедрил FinOps-культуру: cost allocation tags, бюджеты по командам,
еженедельные cost reviews
• Оптимизировал Kubernetes resource utilization через Vertical Pod Autoscaler
и rightsizing, сократил overprovisioning с 45% до 12%
• Перевел 60% compute на Spot Instances с graceful handling interruptions,
внедрил S3 Intelligent-Tiering
• Результат: снижение cloud spending с $35K/месяц до $20K/месяц (экономия
$180K/год или 43%) при росте нагрузки на 200%
Senior DevOps Engineer | FinTech "BankTech Solutions" | Москва
Июнь 2018 – Декабрь 2020
• Построил CI/CD-инфраструктуру для 15 микросервисов банковской системы
на базе GitLab CI и Spinnaker с multi-stage deployments (dev → staging → canary → prod)
• Внедрил Vault для централизованного управления секретами (API keys, DB credentials,
certificates), интегрировал с Kubernetes через CSI driver
• Настроил compliance-мониторинг для PCI DSS: audit logging, intrusion detection
(Falco), vulnerability scanning (Trivy), Policy as Code с Open Policy Agent
• Разработал disaster recovery стратегию с RPO 5 минут / RTO 1 час, автоматизировал
cross-region backups
• Результат: успешное прохождение PCI DSS Level 1 audit, zero security incidents
за 2 года, сокращение deployment time с 4 часов до 35 минут
DevOps Engineer | E-commerce "MegaMart" | Москва
Март 2017 – Май 2018
• Мигрировал on-premise инфраструктуру из 20 серверов в AWS (EC2, RDS, S3, CloudFront)
• Автоматизировал создание инфраструктуры через Terraform и Ansible, настроил
CI/CD в Jenkins
• Внедрил мониторинг на Zabbix и ELK Stack
• Результат: сокращение costs на 30%, повышение scalability с 1K до 10K RPS
Образование и сертификация
AWS Certified Solutions Architect – Professional — Amazon Web Services, 2023
Certified Kubernetes Administrator (CKA) — CNCF, 2021
HashiCorp Certified: Terraform Associate — HashiCorp, 2020
ITIL Foundation Certificate in IT Service Management — Axelos, 2019
Магистр, Информационные технологии
МФТИ, 2015-2017
Публикации и выступления
• Доклад "Platform Engineering: как мы построили Internal Developer Platform"
на DevOops Conference 2024 (300+ участников)
• Серия из 8 статей на Habr по Kubernetes, Service Mesh и FinOps (50K+ просмотров)
• Ментор в рамках программы "DevOps Mentorship" (помог 12 Junior-инженерам)
Дополнительная информация
Языки: Русский (родной), Английский (C1 — свободно, опыт работы с международными
командами)
Почему это резюме выделяется:
- Масштаб влияния (5M пользователей, команда 5 человек)
- Стратегические проекты (Platform Engineering, multi-cloud)
- Впечатляющие метрики (10x improvement, $180K экономия)
- Leadership и менторство
- Публичная активность (доклады, статьи)
- Топовые сертификации (AWS Professional, CKA)
Образование и сертификации: что имеет вес в 2025
Для DevOps-инженера сертификации часто важнее диплома о высшем образовании. Работодатели знают, что практические навыки можно получить вне университета, и ценят подтвержденную экспертизу.
Топ-10 сертификаций для DevOps в 2025
| Сертификация | Ценность | Кому подходит |
|---|---|---|
| Certified Kubernetes Administrator (CKA) | Очень высокая | Middle+ |
| AWS Certified Solutions Architect – Associate | Высокая | Все уровни |
| AWS Certified DevOps Engineer – Professional | Очень высокая | Senior+ |
| HashiCorp Certified: Terraform Associate | Высокая | Junior+ |
| Google Cloud Professional Cloud Architect | Высокая | Middle+ |
| Certified Kubernetes Security Specialist (CKS) | Высокая | Senior+ |
| AWS Certified SysOps Administrator | Средняя | Junior/Middle |
| Microsoft Azure Administrator | Средняя | Для Azure-фокуса |
| Prometheus Certified Associate | Средняя | Junior/Middle |
| Linux Foundation Certified System Administrator | Средняя | Junior |
Как правильно указывать в резюме
✅ Хорошо:
Сертификации
Certified Kubernetes Administrator (CKA) — Cloud Native Computing Foundation, 2024
Credential ID: CKA-2024-123456
Verification: https://ti-user-certificates.s3.amazonaws.com/...
AWS Certified Solutions Architect – Associate — Amazon Web Services, 2023
Credential ID: AWS-SAA-2023-789012
❌ Плохо:
Сертификаты: CKA, AWS, Terraform (где-то есть)
Совет эксперта: Всегда указывайте год получения сертификата и добавляйте Credential ID или ссылку на верификацию. Многие сертификаты имеют срок действия (CKA — 3 года, AWS — 3 года), и рекрутер должен понимать, актуальны ли ваши знания.
Как компенсировать отсутствие профильного образования
Если у вас нет диплома в IT-сфере (экономист, физик, самоучка), это не проблема. DevOps — одна из немногих областей, где практические навыки важнее формального образования.
Стратегия компенсации:
1. Получите топовые сертификации: CKA + AWS SA Associate — это минимум для Middle уровня
2. Покажите реальные проекты: 3-5 качественных pet-проектов на GitHub с детальной документацией стоят больше, чем диплом
3. Документируйте обучение:
Профессиональная переподготовка
DevOps Engineer Professional — Otus, 2024
400 часов практики, 12 реальных проектов, итоговая работа:
развертывание Kubernetes-кластера с мониторингом для e-commerce приложения
Cloud & Infrastructure — Coursera (Google Cloud), 2023
Специализация из 6 курсов: GCP Fundamentals, Kubernetes Engine, Terraform
4. Подчеркните релевантный опыт из прошлого:
Если раньше работали системным администратором, аналитиком, разработчиком — покажите, как этот опыт помогает в DevOps:
Предыдущий опыт, релевантный для DevOps
System Administrator | IT-компания "TechCorp" | 2019-2021
• Администрировал 50+ Linux-серверов (Ubuntu, CentOS)
• Настраивал и поддерживал NGINX, Apache, PostgreSQL, MySQL
• Автоматизировал резервное копирование и мониторинг через Bash-скрипты
Навыки: Linux, Bash, networking, troubleshooting — критичны для DevOps
Частые ошибки и как их избежать
Даже опытные инженеры допускают ошибки в резюме, которые стоят им интересных предложений. Разберем топ-7 критических промахов.
Ошибка №1: "Простыня" технологий без контекста
❌ Плохо:
Навыки: AWS, Azure, GCP, Docker, Kubernetes, OpenShift, Mesos, Nomad,
Jenkins, GitLab CI, CircleCI, Travis CI, TeamCity, Bamboo, Terraform,
Ansible, Puppet, Chef, SaltStack, CloudFormation, ARM Templates,
Python, Go, Java, Ruby, Bash, PowerShell, Prometheus, Grafana...
(список продолжается)
Проблема: Это выглядит как попытка обмануть ATS или говорит о поверхностном знании.
Решение: Оставьте 15-20 технологий, которыми реально владеете, сгруппируйте по категориям:
✅ Хорошо:
Контейнеризация: Docker, Kubernetes, Helm
CI/CD: GitLab CI, Jenkins
IaC: Terraform, Ansible
Cloud: AWS (EC2, EKS, S3, RDS, Lambda)
Ошибка №2: Отсутствие метрик и результатов
❌ Плохо:
• Настраивал CI/CD пайплайны
• Занимался мониторингом
• Работал с AWS
• Оптимизировал инфраструктуру
Проблема: Непонятно, какую ценность вы создали. Это просто список обязанностей.
Решение: Каждый пункт должен содержать результат с цифрами:
✅ Хорошо:
• Внедрил CI/CD с GitLab CI для 8 микросервисов, сократив время релиза
с 2 часов до 15 минут (8x improvement)
• Построил мониторинг на Prometheus/Grafana с 150+ метриками, снизив MTTR
с 1.5 часов до 18 минут
• Мигрировал приложение в AWS EKS, обеспечив масштабирование от 2 до 20 подов
и повысив uptime до 99.8%
• Оптимизировал затраты через rightsizing и Reserved Instances, сократив
расходы на $25K/год (32%)
Ошибка №3: Устаревшие технологии без пояснений
❌ Плохо:
Виртуализация: VMware, VirtualBox
CI/CD: SVN, CVS
Контейнеры: LXC
Проблема: Создается впечатление, что вы отстали от индустрии лет на 10.
Решение: Либо уберите совсем, либо дайте контекст:
✅ Хорошо:
Контейнеризация: Docker, Kubernetes (основное), LXC (поддержка legacy-систем)
Системы контроля версий: Git (основное), SVN (миграция legacy-проектов)
Ошибка №4: Резюме на 5+ страниц
Проблема: Рекрутер тратит 30-60 секунд на первичный просмотр. Если резюме длинное, ключевая информация теряется.
Решение:
- Junior: 1-1.5 страницы (максимум 2)
- Middle: 2 страницы
- Senior/Lead: 2-3 страницы
Что сокращать:
- Опыт работы старше 7-10 лет (кратко или совсем убрать)
- Избыточные детали (не нужно описывать каждый проект за всю карьеру)
- Нерелевантный опыт (работа барменом 10 лет назад не имеет значения)
Ошибка №5: Общие фразы вместо конкретики
❌ Плохо:
• Быстро обучаюсь
• Стрессоустойчивый
• Командный игрок
• Внимательный к деталям
Проблема: Эти фразы ничего не значат без подтверждения.
Решение: Покажите через примеры:
✅ Хорошо:
• Освоил Kubernetes за 2 месяца (с нуля до CKA сертификации) и применил
в production-проекте
• Руководил incident response для 15+ критических инцидентов, всегда
укладывался в RTO 1 час
• Провел 8 воркшопов по GitOps для 3 команд разработки, написал 50 страниц
внутренней документации
• Выявил и исправил критическую уязвимость в CI/CD пайплайне до того,
как она была эксплуатирована
Ошибка №6: Игнорирование ATS-оптимизации
Проблема: 75% крупных компаний используют ATS-системы, которые сканируют резюме на ключевые слова. Если их нет, резюме отсеется автоматически.
Решение:
- Используйте точные названия технологий из вакансии: Если в описании указано "Kubernetes", используйте "Kubernetes", а не "K8s"
- Структурируйте заголовки стандартно: "Опыт работы", "Навыки", "Образование" (не "Моя история" или "Что я умею")
- Формат: PDF или DOCX (не изображения, не сложные шаблоны с таблицами)
- Включайте аббревиатуры И расшифровку:
CI/CD (Continuous Integration/Continuous Deployment): GitLab CI, Jenkins
IaC (Infrastructure as Code): Terraform, Ansible
Ошибка №7: Нет ссылки на GitHub/портфолио
Проблема: Для DevOps-инженера это критично. Работодатель хочет видеть ваш код.
Решение:
1. Обязательно укажите GitHub в контактах
2. Закрепите (pin) 3-5 лучших репозиториев:
- Terraform-модули
- Ansible-плейбуки
- Kubernetes манифесты или Helm charts
- CI/CD примеры
- Мониторинг (например, Grafana dashboards as code)
3. Убедитесь, что в репозиториях есть:
- Подробный README с описанием задачи, решения и результатов
- Комментарии в коде
- Понятная структура папок
- Примеры использования
4. Если коммерческий код под NDA: Создайте анонимизированные примеры или pet-проекты, демонстрирующие аналогичные навыки
Чек-лист: финальная проверка резюме перед отправкой
Перед тем как нажать "Отправить", пройдитесь по этому чек-листу. Один пропущенный пункт может стоить вам собеседования.
Структура и форматирование
- Резюме начинается с ФИО и должности (без фото, если не требуется)
- Контакты указаны полностью: телефон, email, GitHub, город
- Все ссылки рабочие и ведут на актуальные профили
- Разделы идут в логичном порядке: О себе → Навыки → Опыт → Образование
- Формат PDF или DOCX (не изображение)
- Нет опечаток и грамматических ошибок (прогоните через Grammarly или Language Tool)
Раздел "О себе" (Summary)
- Указан уровень (Junior/Middle/Senior) и опыт в годах
- Перечислены 5-7 ключевых технологий
- Есть хотя бы одно достижение с метрикой
- Понятно, какую позицию ищете и почему
- Объем: 3-5 предложений (не больше)
Технические навыки
- Навыки сгруппированы по категориям (Контейнеризация, CI/CD, IaC и т.д.)
- Включены ключевые слова из вакансии
- Указаны актуальные технологии 2026 года (Kubernetes, Terraform, GitOps)
- Нет "простыни" из 50+ технологий
- Убраны или помечены как legacy устаревшие инструменты
Опыт работы
- Для каждой позиции указаны: название компании, должность, период работы, город
- Достижения описаны по формуле: действие + технологии + результат с метриками
- Использованы глаголы действия (внедрил, оптимизировал, сократил)
- Есть конкретные цифры: проценты, время, деньги, количество
- Опыт старше 10 лет описан кратко или исключен
- Для Junior: pet-проекты описаны детально, как коммерческие задачи
Образование и сертификации
- Сертификаты указаны с годом получения и Credential ID
- Приоритет отдан релевантным сертификациям (CKA, AWS, Terraform)
- Если нет IT-образования, компенсировано курсами и проектами
GitHub и портфолио
- Ссылка на GitHub работает и ведет на активный профиль
- Закреплены 3-5 лучших репозиториев
- В репозиториях есть подробные README файлы
- Последний коммит не старше 6 месяцев (показывает активность)
ATS-оптимизация
- Заголовки разделов стандартные ("Опыт работы", не "Моя карьера")
- Ключевые слова из вакансии включены в текст естественным образом
- Технологии указаны полными названиями (Kubernetes, а не K8s)
- Формат простой, без сложных таблиц и графики
Финальная проверка
- Объем резюме: Junior — 1-2 страницы, Middle — 2 страницы, Senior — 2-3 страницы
- Все метрики проверены и реалистичны
- Нет стоп-слов: "динамично развивающийся", "широкий спектр задач"
- Тон профессиональный, без сленга и эмодзи
- Резюме адаптировано под конкретную вакансию (технологии, терминология)
- Название файла осмысленное: "Иванов_Алексей_DevOps_Engineer.pdf"
Часто задаваемые вопросы
Нужно ли писать сопроводительное письмо к резюме?
Короткий ответ: Зависит от вакансии.
В каких случаях обязательно:
- Если это явно указано в требованиях вакансии
- При отклике в зарубежную или международную компанию
- Если хотите объяснить нестандартную ситуацию (перерыв в работе, смена сферы)
- Для Senior/Lead позиций, где важна коммуникация
Когда можно пропустить:
- Быстрый отклик через HeadHunter/LinkedIn на типовую вакансию
- Если резюме уже содержит все нужные пояснения
Структура эффективного письма (3-4 абзаца):
- Вступление: Почему заинтересовала именно эта вакансия и компания
- Ценность: 2-3 ключевых достижения, релевантных для позиции
- Мотивация: Что вы хотите привнести в команду
- Призыв к действию: Готовы обсудить детали на встрече
Совет эксперта: Если пишете сопроводительное письмо, делайте его персонализированным. Упомяните конкретный продукт компании, технологии из стека или недавнюю новость. Шаблонные письма хуже, чем их отсутствие.
Как описать pet-проект, чтобы он выглядел серьезно?
Структура описания pet-проекта:
Название проекта: [Краткое описание задачи]
Период: [Когда делали]
• Контекст: Какую проблему решали (даже если учебную, формулируйте как бизнес-задачу)
• Технологии: Какой стек использовали
• Решение: Что конкретно реализовали
• Результат: Измеримый итог (скорость, масштаб, стабильность)
• Ссылка на репозиторий
Пример:
Автоматизированная инфраструктура для SaaS-приложения
Июль 2024 – Сентябрь 2024
• Задача: Создать production-ready инфраструктуру для развертывания
multi-tenant SaaS с требованиями к масштабируемости и мониторингу
• Спроектировал и развернул в AWS: VPC с публичными/приватными подсетями,
EKS кластер, RDS PostgreSQL Multi-AZ, ALB с SSL
• Автоматизировал создание инфраструктуры через Terraform (300+ строк IaC
с модульной структурой)
• Настроил CI/CD в GitHub Actions с тестами, security-сканированием
(Trivy) и blue-green деплоем
• Внедрил мониторинг (Prometheus + Grafana) с 8 дашбордами и алертингом
• Результат: полностью автоматизированный процесс от коммита до production
за 12 минут, инфраструктура выдерживает нагрузку 1K RPS с автомасштабированием
• GitHub: github.com/username/saas-infrastructure
Как адаптировать резюме под конкретную вакансию?
Базовый процесс адаптации (15-20 минут на вакансию):
1. Проанализируйте описание вакансии:
- Выпишите требуемые технологии (особенно те, что повторяются)
- Обратите внимание на формулировки (GitOps, Infrastructure as Code, Monitoring)
- Определите уровень (какие задачи, какой масштаб)
2. Обновите раздел "О себе":
- Включите 2-3 ключевых технологии из вакансии
- Адаптируйте свои достижения под их потребности
Пример:
Если в вакансии: "Ищем DevOps для внедрения Kubernetes и GitOps"
Ваш Summary:
DevOps Engineer с 3+ годами опыта контейнеризации и оркестрации.
Специализируюсь на Kubernetes и GitOps-практиках. В текущем проекте
мигрировал 12 микросервисов в EKS и внедрил ArgoCD, сократив время
релизов с 40 до 8 минут...
3. Переставьте навыки по приоритету:
- То, что нужно работодателю, — в начало списка
4. Выделите релевантный опыт:
- Если у вас 5 проектов, а в вакансии нужен опыт с AWS и Terraform,
подробно опишите именно тот проект, где вы это делали
5. Используйте их терминологию:
- Если они пишут "Site Reliability Engineer", используйте это, а не "DevOps Engineer"
- Если упоминают "Infrastructure as Code", используйте именно эту фразу, а не "IaC"
Что делать, если был перерыв в работе больше 6 месяцев?
Честность + проактивность = решение проблемы
Варианты объяснения перерыва:
1. Обучение:
Карьерный перерыв для переподготовки в DevOps
Январь 2024 – Июнь 2024
• Прошел профессиональную переподготовку по DevOps (400 часов практики)
• Получил 3 сертификации: AWS SA Associate, CKA, Terraform Associate
• Реализовал 5 pet-проектов: CI/CD пайплайны, Kubernetes кластеры,
IaC с Terraform
• Результат: готов к работе Middle DevOps-инженером с актуальным
стеком технологий
2. Фриланс/контракты:
Фриланс-проекты
Март 2024 – Август 2024
Клиент: Стартап HealthTech (NDA)
• Настроил AWS инфраструктуру и CI/CD для MVP продукта
• Результат: сокращение времени деплоя с ручных 3 часов до автоматических 15 минут
Клиент: E-commerce компания
• Оптимизировал облачные расходы, сократив затраты на 28%
3. Личные обстоятельства (кратко, без деталей):
Карьерный перерыв по личным обстоятельствам
Апрель 2024 – Сентябрь 2024
В этот период:
• Поддерживал актуальность навыков через pet-проекты на GitHub
• Получил сертификацию CKA
• Изучал новые технологии: Istio, OpenTelemetry, FinOps практики
Совет эксперта: Не оставляйте пробелы в хронологии без объяснений. Работодатель все равно спросит, так что лучше сразу дать короткое, честное пояснение прямо в резюме. Главное — показать, что перерыв был продуктивным или вы готовы быстро вернуться в форму.
Указывать ли зарплатные ожидания в резюме?
Зависит от платформы и региона:
Указывайте, если:
- Платформа требует (HeadHunter делает это обязательным полем)
- Хотите отсеять вакансии с неподходящим бюджетом
- У вас Senior/Lead уровень с четким пониманием рынка
Не указывайте, если:
- Отправляете резюме напрямую в компанию (в письме можно обсудить)
- Вы Junior и готовы рассматривать разные предложения
- Хотите оставить пространство для переговоров
Как формулировать:
✅ Хорошо:
Зарплатные ожидания: от 250 000 руб. на руки
или
Зарплатные ожидания: 250 000 – 300 000 руб. (обсуждаемо в зависимости
от проекта и условий)
❌ Плохо:
Зарплата: любая
Зарплата: договорная (это ни о чем не говорит)
Нужно ли указывать причины ухода с предыдущих мест?
Короткий ответ: Нет, в резюме это не нужно.
Причины ухода обсуждаются на собеседовании, если рекрутер спросит. В резюме это занимает место и может создать негативное впечатление.
Исключения (когда можно кратко упомянуть):
- Релокация: "(переезд в другой город)"
- Закрытие проекта/компании: "(компания прекратила деятельность)"
- Окончание контракта: "(завершение срочного проекта)"
Middle DevOps Engineer | Startup "TechCo" | Москва
Июнь 2022 – Декабрь 2023 (компания закрылась после прекращения финансирования)
Заключение: ваш следующий шаг
Резюме DevOps-инженера — это не просто формальность для HR-отдела. Это техническая спецификация вашей ценности, написанная на языке метрик и бизнес-результатов.
Главные принципы, которые вы должны вынести из этого руководства:
- Метрики решают все: Каждое достижение должно содержать измеримый результат — время, проценты, деньги, масштаб
- Адаптация под вакансию: Базовое резюме — это шаблон. Тратьте 15-20 минут на персонализацию под каждую интересную позицию
- GitHub — ваша витрина: Для DevOps-инженера это так же важно, как портфолио для дизайнера
- Структура и читабельность: Рекрутер тратит 30 секунд на первичный просмотр. Помогите ему быстро найти ключевую информацию
- Честность + проактивность: Не преувеличивайте, но и не преуменьшайте свои достижения. Если чего-то не хватает (сертификации, опыта с технологией) — покажите, как планируете это компенсировать
Ваш action plan на следующие 7 дней:
- День 1-2: Обновите базовую версию резюме по структуре из этой статьи
- День 3-4: Трансформируйте все обязанности в достижения с метриками (пересмотрите старые задачи — везде найдутся цифры)
- День 5: Проверьте и обновите GitHub: закрепите лучшие проекты, допишите README
- День 6: Получите фидбек от коллеги или ментора в DevOps-сфере
- День 7: Адаптируйте резюме под 3-5 конкретных вакансий и отправьте
Рынок DevOps-инженеров в 2026 году остается горячим — компании активно ищут специалистов, которые могут автоматизировать процессы, повышать надежность и оптимизировать затраты. Ваша задача — не просто найти работу, а найти ту позицию, где вы будете расти, влиять на продукт и получать удовольствие от решения интересных задач.
Сильное резюме — это первый шаг к этой цели. Не экономьте время на его создание. Один хорошо составленный документ может открыть десятки дверей.
Следующий шаг после отправки резюме: Подготовка к техническому собеседованию. Но это уже тема для отдельной статьи.
Удачи в поиске! Пусть ваши пайплайны всегда будут зелеными, а uptime — 99.99%.

1000+ офферов получено
Устали искать работу? Мы найдём её за вас
Quick Offer улучшит ваше резюме, подберёт лучшие вакансии и откликнется за вас. Результат — в 3 раза больше приглашений на собеседования и никакой рутины!