NDA
150 000 ₽ – 400 000 ₽
AI-разработчик / Python backend разработчик
В офисе
Python · FastAPI · Django · Flask · LangChain · LangGraph · RAG · LLM · GigaChat · OpenAI · Pandas · NumPy · SciPy · Scrapy · OOP · API
+16 навыковai разработчик - готовый пример резюме для профессии и руководство по составлению с советами бесплатно.
Резюме AI-разработчика — это не просто список технологий и проектов. Это ваш первый ML-продукт, который нужно «обучить» под конкретную вакансию. Рекрутер тратит 6-8 секунд на первичный просмотр, а ATS-система (автоматический скрининг резюме) может отсеять вас еще раньше из-за отсутствия ключевых слов.
В этом руководстве вы найдете пошаговую инструкцию по созданию резюме, которое пройдет автоматические фильтры и заинтересует технического специалиста. Мы разберем конкретные примеры для Junior, Middle и Lead-разработчиков, покажем, как превратить описание обязанностей в измеримые достижения, и дадим готовые формулировки для разных секций.
Специфика профессии AI/ML-инженера заключается в том, что нужно одновременно демонстрировать три типа компетенций:
Рекрутеры ищут не просто человека, который знает PyTorch. Им нужен специалист, который может взять бизнес-задачу («снизить отток клиентов»), превратить ее в ML-задачу (например, классификация с предсказанием churn), реализовать решение и показать измеримый результат («снижение оттока на 18%, что дало экономию $240K в год»).
Совет эксперта: Ваше резюме должно отвечать на три вопроса: что вы умеете (технологии), что вы сделали (проекты) и какую пользу это принесло (метрики бизнеса). Если хотя бы один из этих элементов отсутствует — резюме теряет 50% убедительности.
Эффективное резюме AI/ML-инженера состоит из следующих блоков:
Далее разберем каждый раздел подробно с примерами для разных уровней специалистов.
Название должности в резюме должно совпадать с тем, как вакансию формулирует работодатель. Это критично для прохождения ATS-систем, которые ищут точные совпадения ключевых слов.
Рекомендуемые варианты:
Избегайте размытых формулировок:
Сразу под должностью укажите:
Пример оформления:
Иван Петров
Machine Learning Engineer
Email: ivan.petrov.ml@gmail.com | Тел: +7 (999) 123-45-67
Москва
GitHub: github.com/ivanpetrov | Kaggle: kaggle.com/ivanpetrov | LinkedIn: linkedin.com/in/ivanpetrov
Совет эксперта: GitHub для AI-разработчика — это как портфолио для дизайнера. Отсутствие публичного кода снижает ваши шансы на 40%, особенно на позициях Junior и Middle. Даже если коммерческие проекты под NDA, создайте 2-3 pet-проекта и выложите их с подробным README.
Сравните, как ИИ-резюмейкер Quick Offer превращает резюме с hh.ru в профессиональное

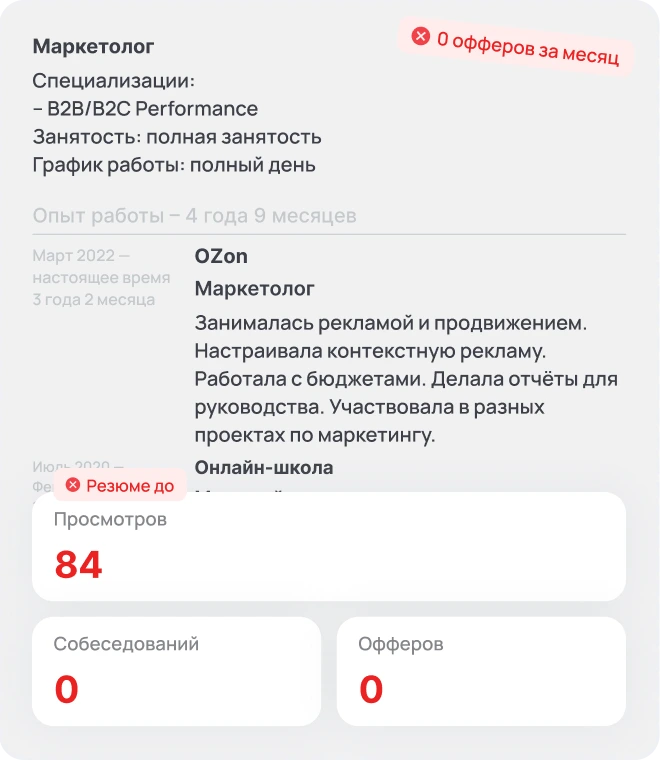
Это первый текстовый блок, который прочитают после заголовка. Цель — за 3-4 предложения (не более 300 символов) показать вашу ценность и уровень экспертизы.
Структура: Опыт + ключевая специализация + главное достижение/компетенция + что ищете
Для Junior (0-1 год коммерческого опыта):
Junior ML Engineer с опытом разработки моделей компьютерного зрения и NLP.
Участвовал в 5 Kaggle-соревнованиях (лучший результат — топ-15%). Реализовал
3 pet-проекта на PyTorch с развертыванием через FastAPI. Ищу позицию в продуктовой
команде для работы над реальными ML-задачами.
Почему работает:
Для Middle (2-4 года опыта):
ML Engineer с 3-летним опытом разработки и внедрения моделей рекомендаций
и прогнозной аналитики. Создал рекомендательную систему, увеличившую
конверсию на 28% (500K+ пользователей). Опыт работы с полным циклом:
от исследования и обучения до deployment и мониторинга в production.
Специализация: Python, TensorFlow, MLOps (Docker, Kubernetes, MLflow).
Почему работает:
Для Senior/Lead (5+ лет опыта):
Senior ML Engineer с 6-летним опытом проектирования ML-архитектур
и управления командами. Построил ML-платформу для автоматизации
underwriting, обрабатывающую 10M+ заявок/год с экономией $2M.
Опыт в финтех, e-commerce и телекоме. Экспертиза: архитектура
распределенных ML-систем, NLP, CV, MLOps. Ищу роль ML Lead
для создания AI-продуктов с нуля.
Почему работает:
| Плохо | Почему не работает | Хорошо |
|---|---|---|
| «Ответственный и целеустремленный специалист» | Общие слова без подтверждения | «Выполнил 12 проектов в срок, 9 из них превысили плановые метрики» |
| «Имею опыт работы с нейронными сетями» | Слишком широко, нет конкретики | «Разработал 5 CNN-моделей для задач классификации и детекции объектов» |
| «Разбираюсь в машинном обучении» | Звучит неуверенно | «3 года разрабатываю и внедряю ML-модели для прогнозирования оттока» |
| «Знаю Python, TensorFlow, PyTorch...» | Просто список технологий | «Создал production-ready pipeline на TensorFlow, обрабатывающий 1M запросов/день» |
Раздел с навыками выполняет две функции: позволяет ATS-системе найти ключевые слова и дает рекрутеру быстро оценить ваш стек.
Не сваливайте все технологии в одну кучу. Разделите их на логические категории:
Технические навыки:
Языки программирования: Python, SQL, C++ (базовый уровень)
ML/DL фреймворки: PyTorch, TensorFlow, Scikit-learn, Keras, XGBoost, LightGBM
Работа с данными: Pandas, NumPy, Matplotlib, Seaborn, Apache Spark
MLOps и инфраструктура: Docker, Kubernetes, MLflow, DVC, Git, CI/CD (GitHub Actions)
Облачные платформы: AWS (SageMaker, EC2, S3), Google Cloud Platform (Vertex AI)
Базы данных: PostgreSQL, MongoDB, Redis, Vector DB (Pinecone, Weaviate)
Дополнительные инструменты: FastAPI, Flask, Jupyter, Streamlit, Airflow
Если вы работаете с трендовыми технологиями, выделите их отдельно:
Специализация в Generative AI и LLM:
- Fine-tuning больших языковых моделей (GPT-4, LLaMA, Mistral)
- RAG (Retrieval-Augmented Generation) с использованием LangChain
- Prompt Engineering и Chain-of-Thought
- Vector databases для семантического поиска (Pinecone, ChromaDB)
- Stable Diffusion, ControlNet для генерации изображений
Упоминание LLM и Generative AI в 2026 году критически важно — 65% вакансий для AI-разработчиков требуют опыта работы с большими языковыми моделями.
Не рекомендуется: Визуальные шкалы («Python ⭐⭐⭐⭐⭐») или процент владения («Python — 90%») — это субъективно и не дает рекрутеру реальной информации.
Рекомендуется: Если хотите показать уровень, используйте контекст:
Но самый сильный способ показать уровень владения — конкретные проекты в разделе «Опыт работы».
Совет эксперта: Адаптируйте список навыков под конкретную вакансию. Если в требованиях указано «обязательно PyTorch», вынесите его в начало списка фреймворков. ATS-системы часто ранжируют кандидатов по тому, насколько рано в резюме встречаются ключевые слова из описания вакансии.
Это самый важный раздел резюме. Здесь вы должны показать не просто «чем занимались», а «какую пользу принесли».
Задача → Подход/технологии → Измеримый результат → Влияние на бизнес
Каждое описание должно отвечать на четыре вопроса:
Контекст: У Junior часто нет коммерческого опыта, но есть учебные проекты, стажировки, хакатоны, Kaggle.
Плохой пример (список обязанностей):
Стажер Data Scientist | Компания XYZ | июнь 2024 — август 2024
- Обучал модели машинного обучения
- Работал с данными
- Писал код на Python
Почему не работает: Нет конкретики, нет результатов, непонятно, что именно делали и какой был эффект.
Хороший пример (измеримые достижения):
Junior ML Engineer (стажировка) | Компания XYZ | июнь 2024 — декабрь 2024
Разработка системы классификации клиентских обращений
- Обучил модель классификации текстов (BERT) для автоматической
категоризации входящих запросов в службу поддержки
- Подготовил и разметил датасет из 15K запросов, провел аугментацию
данных, что улучшило F1-score с 0.78 до 0.86
- Реализовал inference pipeline с использованием FastAPI,
обрабатывающий 100+ запросов/мин
- Результат: автоматизировано 60% обращений, сокращено время
первичной обработки на 40%
Технологии: Python, PyTorch, Transformers (Hugging Face), FastAPI, Docker, PostgreSQL
Почему работает:
Пример описания pet-проекта для Junior:
Если у вас нет коммерческого опыта, pet-проекты с GitHub — это ваш опыт.
Pet-проекты (личное портфолио)
Система рекомендаций фильмов на основе collaborative filtering
- Реализовал рекомендательную систему для датасета MovieLens (25M оценок)
- Сравнил 4 подхода: SVD, NMF, neural collaborative filtering,
LightFM (гибрид content-based + CF)
- Лучший результат: RMSE 0.84, что на 12% лучше baseline (популярные фильмы)
- Развернул веб-приложение на Streamlit с API на FastAPI,
добавил A/B-тестирование рекомендаций
- Документация и код: github.com/username/movie-recommender (150+ звезд)
Технологии: Python, PyTorch, FastAPI, Streamlit, Redis, Docker
Подбираем лучшие вакансии и откликаемся за вас. До 100 автооткликов в день.

Контекст: Middle должен показать опыт работы над реальными продуктовыми задачами, самостоятельность в принятии решений и измеримый business impact.
Плохой пример:
ML Engineer | Компания ABC | январь 2023 — настоящее время
- Разрабатывал рекомендательную систему
- Оптимизировал модели
- Работал в команде с бэкендом
Хороший пример:
ML Engineer | E-commerce компания ABC | январь 2023 — настоящее время
Разработка и внедрение персонализированной рекомендательной системы
- Спроектировал two-tower neural network для персонализации
товарных рекомендаций с учетом user embeddings и item features
- Провел offline-эксперименты на исторических данных (50M взаимодействий),
выбрал оптимальную архитектуру по балансу точности и latency
- Внедрил модель в production через gRPC API с latency <50ms
при 2000+ RPS, настроил мониторинг метрик (Prometheus + Grafana)
- Результат: рост CTR рекомендаций на 23%, увеличение среднего
чека на 15%, охват 500K+ активных пользователей/месяц
- Провел 3 итерации A/B-тестов, задокументировал подходы
для использования другими командами
Создание NLP-пайплайна для анализа отзывов
- Разработал систему sentiment analysis и извлечения аспектов
из отзывов на товары (fine-tuned RuBERT на 100K размеченных отзывов)
- Автоматизировал pipeline обработки с помощью Airflow:
сбор, препроцессинг, inference, сохранение результатов
- Точность классификации тональности: 91% (на 7% выше baseline VADER)
- Результат: продуктовая команда получила инструмент для
мониторинга качества товаров в реальном времени, выявлено
15 категорий с системными проблемами
Технологии: Python, PyTorch, TensorFlow Serving, Airflow,
Docker, Kubernetes, PostgreSQL, Redis, AWS (EC2, S3, SageMaker)
Почему работает:
Контекст: Senior/Lead фокусируется на архитектуре систем, управлении командой, стратегических решениях и ROI от AI-инициатив.
Плохой пример:
Senior ML Engineer | Компания TechCorp | 2020 — настоящее время
- Руководил командой ML-инженеров
- Разрабатывал ML-стратегию
- Внедрял новые технологии
Хороший пример:
Lead ML Engineer | Финтех-компания TechCorp | март 2020 — настоящее время
Построение ML-платформы для автоматизации кредитного скоринга
- Спроектировал end-to-end ML-платформу для оценки кредитоспособности,
обрабатывающую 10M+ заявок/год
- Выбрал tech stack (Feature Store на Feast, обучение на Kubeflow,
serving через TensorFlow Serving + Seldon Core), обосновал архитектуру
перед C-level командой
- Модель градиентного бустинга (LightGBM) с 150+ признаками:
Gini coefficient 0.72, снижение default rate на 18% vs. предыдущая система
- Бизнес-результат: экономия $2M/год за счет снижения дефолтов
и автоматизации процесса (сокращение времени принятия решения с 48 часов до 5 минут)
- Внедрил систему мониторинга data drift и model degradation,
что позволило выявлять проблемы на 3 недели раньше
Управление командой и наставничество
- Руководил кросс-функциональной командой из 5 ML-инженеров,
2 data engineers и 1 MLOps-специалиста
- Выстроил процессы code review, проектирования экспериментов,
документирования решений
- Провел 10+ воркшопов для продуктовых команд по возможностям ML,
что привело к инициации 4 новых AI-проектов
Внедрение LLM-решений для автоматизации клиентской поддержки
- Исследовал применимость LLM (GPT-4, fine-tuned LLaMA)
для генерации ответов на запросы клиентов
- Реализовал RAG-систему с векторной базой знаний (1000+ документов)
на Pinecone, снизил hallucination rate до 5%
- Пилот показал сокращение нагрузки на поддержку на 35%,
CSAT вырос с 4.2 до 4.6/5
- Разработал roadmap масштабирования решения на другие направления поддержки
Технологии: Python, PyTorch, TensorFlow, Kubeflow, Feast, Seldon Core,
LangChain, Pinecone, PostgreSQL, Kafka, AWS (SageMaker, Lambda, S3),
Terraform, Grafana
Почему работает:
Начинайте каждый пункт с сильного глагола действия. Это делает текст динамичным и показывает вашу активную роль.
Для разработки и внедрения:
Для исследований и экспериментов:
Для оптимизации:
Для работы с данными:
Для командной работы:
| Было (слабо) | Стало (сильно) | Почему лучше |
|---|---|---|
| Работал над NLP-проектами | Разработал чат-бота на fine-tuned GPT-3.5, обрабатывающего 10K запросов/день, что снизило нагрузку на службу поддержки на 40% | Конкретный проект, технология, масштаб, бизнес-результат |
| Обучал нейронные сети | Обучил CNN-модель (ResNet-50) для детекции дефектов на производстве с точностью 94%, сократив время проверки качества на 60% | Указана архитектура, метрика точности, измеримый эффект |
| Оптимизировал модели | Ускорил inference модели рекомендаций с 200ms до 45ms через квантизацию и TensorRT, что позволило обслуживать на 3x больше пользователей на том же железе | Конкретные цифры до/после, технология оптимизации, бизнес-эффект |
| Работал с данными | Построил ETL-пайплайн на Airflow для обработки 5TB логов/день, автоматизировал feature engineering для 200+ признаков, сократив время подготовки данных с 2 дней до 2 часов | Инструмент, объем данных, конкретная экономия времени |
| Участвовал в развитии продукта | Провел 5 итераций A/B-тестов рекомендательной модели, проанализировал результаты для 100K пользователей, выбрал победившую версию, увеличившую retention на 12% | Процесс работы, масштаб, метрика продукта |
AI создаст 3 письма под ваше резюме и подберёт лучшее под каждую вакансию.

Для AI/ML-позиций релевантным считается образование в области:
Формат указания:
Образование:
Московский государственный университет имени М.В. Ломоносова
Магистратура, Прикладная математика и информатика | 2022 — 2024
Диплом: "Применение трансформеров для задач NER в медицинских текстах"
Московский государственный университет имени М.В. Ломоносова
Бакалавриат, Прикладная математика и информатика | 2018 — 2022
Совет эксперта: Если тема дипломной работы релевантна AI/ML, обязательно укажите ее. Это показывает, что вы занимались исследованиями и умеете работать с научными задачами.
В AI-индустрии профильные курсы ценятся высоко, особенно от признанных платформ. Но указывайте только значимые сертификаты, а не все пройденные курсы.
Ценные сертификаты для AI-разработчика:
Формат указания:
Сертификаты:
Deep Learning Specialization | Coursera (Andrew Ng) | 2023
AWS Certified Machine Learning – Specialty | Amazon Web Services | 2024
TensorFlow Developer Certificate | Google | 2023
Не стоит указывать:
Если у вас есть научные публикации, это очень сильный сигнал, особенно для Research Engineer позиций.
Формат:
Публикации:
[1] Петров И., Сидоров А. "Fine-tuning BERT for Russian Named Entity Recognition
in Medical Texts" // Proceedings of Conference on AI, 2024
Ссылка: arxiv.org/abs/2024.xxxxx | Цитирований: 12 (Google Scholar)
[2] Петров И. "Comparative Analysis of Object Detection Models for Retail
Checkout Automation" // Journal of Computer Vision, 2023
Ссылка: doi.org/10.xxxx/xxxxx
Если публикаций нет, но вы делали доклады на митапах или конференциях — это тоже стоит указать:
Выступления:
"Внедрение LLM в production: опыт и подводные камни" | AI Conference Moscow, 2024
"MLOps Best Practices: от эксперимента до продакшена" | ML Meetup, 2023
Для Junior и Middle это может быть важнее коммерческого опыта.
Что указывать:
Пример:
Pet-проекты:
AI-генератор музыки на основе текстовых описаний
Реализовал multimodal модель (CLIP + MusicGen) для генерации музыкальных
композиций по текстовому описанию. Обучил на датасете из 50K треков.
GitHub: github.com/username/music-gen (230 ⭐) | Demo: music-ai.app
Технологии: Python, PyTorch, Transformers, FastAPI, React
Детектор фейковых новостей с объяснением предсказаний
CNN + LSTM модель для классификации новостей + LIME для explainability.
F1-score 0.89 на тестовой выборке.
GitHub: github.com/username/fake-news-detector (85 ⭐)
Технологии: Python, TensorFlow, LIME, Streamlit
Активность на Kaggle — отличный способ показать практические навыки для Junior/Middle.
Формат:
Kaggle Profile: kaggle.com/username | Competitions Expert (топ-5% участников)
Достижения:
- Natural Language Processing with Disaster Tweets — 12 место из 800+ команд (Silver Medal)
- Табличные данные: House Prices Prediction — топ-8% (Bronze Medal)
- Публичные ноутбуки с 500+ upvotes по темам CV и NLP
Для международных компаний и удаленной работы важен английский.
Формат:
Языки:
Русский — родной
Английский — Upper-Intermediate (B2)
- Читаю техническую документацию и research papers
- Участвовал в международных проектах с англоязычными коллегами
- Проходил собеседования на английском
Не преувеличивайте уровень — его проверят на собеседовании.
ATS (Applicant Tracking System) — это программы, которые автоматически сканируют резюме на наличие ключевых слов из описания вакансии. По статистике, 75% резюме отсеиваются на этом этапе.
1. Формат файла:
2. Структура:
3. Ключевые слова:
4. Контактная информация:
Совет эксперта: Создайте базовую версию резюме, а затем адаптируйте ее под каждую конкретную вакансию. Скопируйте ключевые требования из описания и убедитесь, что эти термины присутствуют в вашем резюме (если они действительно отражают ваши навыки).
Проверьте свое резюме:
Проблема: Попытка охватить все возможные роли (Data Scientist, ML Engineer, Data Analyst) в одном резюме.
Решение: Создайте отдельные версии резюме для разных типов позиций. Для AI/ML Engineer акцент на разработке и внедрении моделей, для Research Engineer — на исследованиях и экспериментах.
Плохо:
Навыки: Python, TensorFlow, PyTorch, Docker, Kubernetes, AWS, Git,
SQL, MongoDB, Flask, FastAPI, Scikit-learn, XGBoost...
Хорошо:
ML-фреймворки: TensorFlow (production-проекты), PyTorch (исследования и прототипирование)
MLOps: Docker, Kubernetes (deployment моделей), MLflow (tracking экспериментов)
Контекст использования важнее простого перечисления.
Плохо: "Улучшил производительность модели"
Хорошо: "Сократил время inference с 300ms до 80ms через оптимизацию архитектуры и квантизацию, что позволило обрабатывать на 4x больше запросов/сек"
Цифры делают достижения конкретными и проверяемыми.
ATS действительно ищет ключевые слова, но рекрутер увидит, если вы просто скопировали требования.
Плохо:
"Опыт работы с Python, TensorFlow, PyTorch, разработкой ML-моделей,
работой в команде" (это просто список из требований вакансии)
Хорошо:
"Разработал 7 production-ready ML-моделей на TensorFlow и PyTorch
для задач классификации и регрессии, работая в кросс-функциональной
команде с backend-разработчиками и продакт-менеджерами"
Технические навыки — это 70% успеха, но 30% — это коммуникация, командная работа, умение объяснять сложное простым языком.
Как показать soft skills:
Оптимальная длина:
Если резюме длиннее — сокращайте. Убирайте проекты 5-летней давности, которые не релевантны текущим технологиям.
Перед тем как отправить резюме, пройдитесь по этому списку:
Структура и оформление:
Содержание:
ATS-оптимизация:
Проверка на реальность:
Совет эксперта: Попросите коллегу или ментора просмотреть ваше резюме. Свежий взгляд часто замечает ошибки, которые вы пропустили, и может подсказать, какие достижения стоит выделить сильнее.
Ситуация: Вы не работали 6-12 месяцев (учеба, семейные обстоятельства, поиск работы).
Решение:
Самостоятельное обучение и проекты | июнь 2023 — декабрь 2023
- Прошел специализацию Deep Learning (Coursera)
- Разработал 3 pet-проекта (CV, NLP, рекомендательные системы)
- Участвовал в 4 Kaggle-соревнованиях (топ-20% в 2 из них)
Проблема: Фриланс-проекты часто краткосрочные и разрозненные.
Решение: Объедините их под одним заголовком:
ML Engineer (фриланс) | январь 2023 — настоящее время
Проект 1: Система распознавания документов для финтех-стартапа
- Разработал CNN-модель для классификации и извлечения данных
из паспортов и водительских прав (accuracy 96%)
- Результат: автоматизация обработки 500+ документов/день
Технологии: Python, PyTorch, OpenCV, FastAPI
Проект 2: Чат-бот для автоматизации FAQ интернет-магазина
- Fine-tuned GPT-3.5 на корпусе из 2000 вопросов и ответов
- Внедрил RAG для актуальной информации из каталога товаров
Технологии: LangChain, Pinecone, FastAPI, PostgreSQL
Даже если проекты для разных заказчиков — объединяйте их, чтобы показать разнообразие задач.
Рекомендация: Нет, если только это не обязательное требование работодателя.
Почему:
Если в форме отклика есть обязательное поле, укажите диапазон (например, "от 200,000 до 250,000 руб.") или "обсуждается по результатам собеседования".
Стратегия:
Пример раздела для Junior без опыта:
Практические проекты:
Детектор объектов на основе YOLO для подсчета автомобилей на парковке
- Обучил YOLOv8 на кастомном датасете (3000 размеченных изображений)
- Precision 91%, Recall 88% на тестовой выборке
- Развернул через Flask + Docker, реальное время inference ~30 FPS
GitHub: github.com/username/parking-detector | Demo: youtube.com/watch?v=xxxxx
Kaggle Competitions:
- Titanic (топ-12%), House Prices (топ-15%)
- Публичный ноутбук по feature engineering набрал 200+ upvotes
Правило: Указывайте только то, о чем готовы отвечать на собеседовании.
Как обозначить уровень:
Kubernetes (базовый уровень): использовал для deployment моделей,
настраивал готовые конфигурации
Основные: Python, PyTorch, TensorFlow, Docker, AWS
Дополнительные: C++ (оптимизация), Julia (прототипирование)
Способы:
1. Упоминание актуальных технологий:
- LLM (GPT-4, LLaMA, Claude)
- RAG и LangChain
- Vector databases
- Multimodal models
2. Раздел с курсами и самообучением:
Постоянное обучение:
- Прошел курс "LLM Bootcamp" (Full Stack Deep Learning, 2024)
- Регулярно читаю research papers (arXiv, подписан на ML newsletters)
- Участник локального ML-комьюнити (monthly meetups)
3. Блог или публикации:
- Статьи на Medium/Habr о новых подходах
- Презентации на митапах
Да, это критически важно.
Минимальная адаптация (10 минут):
Глубокая адаптация (30-60 минут):
Совет эксперта: Создайте "базовое" резюме со всеми проектами и достижениями, а затем для каждой вакансии делайте копию и убирайте менее релевантные части. Это быстрее, чем каждый раз писать с нуля.
Резюме — это не цель, а инструмент для получения приглашения на интервью. Даже идеальное резюме не гарантирует оффер, но плохое резюме гарантированно закроет вам дверь.
Три главных принципа, которые нужно запомнить:
Следующие шаги после составления резюме:
Помните: резюме — это живой документ. Обновляйте его после каждого значимого проекта, добавляйте новые технологии, пересматривайте формулировки. Через полгода ваше резюме должно отличаться от текущего, потому что вы растете как специалист.
Удачи в поиске работы мечты в AI!

1000+ офферов получено
Quick Offer улучшит ваше резюме, подберёт лучшие вакансии и откликнется за вас. Результат — в 3 раза больше приглашений на собеседования и никакой рутины!